

During one of the recent working days, I was tasked with fuzzing some Go applications. That's something I had not done in a while, so my first course of action was to research the current state of the art of the tooling landscape. After like a couple of hours of fiddling and researching, I decided to just note down what my experience was like as someone who is very familiar with fuzzing itself but has not been fiddling with Go for a long time and not a lot in the past either.
Hot take: Fuzzing itself is being a well-established technique in software security, Go's fuzzing ecosystem lacks a clear, go-to state-of-the-art fuzzer.
This post delves into the current landscape of Go fuzzing, examining the tools, developments, and shortcomings, while providing technical examples and references for more in-depth understanding.
The past
This period is best described as the time-frame when I started looking at Go fuzzing, back in the days. It's been a while, so let's quickly recap where we started from.
go-fuzz
One of the earliest fuzzing tools for Go was go-fuzz. Despite its initial promise and vast success (just check the "trophy section"), the tool has become deprecated, particularly since the release of Go 1.18, as discussed in issue #329. Interestingly, despite its deprecated status, go-fuzz still seems to function at the moment based on my not so exhaustive testing. As also stated in the aforementioned issue, the state of it is literally "if shit hits the fan, nobody will be there to clean up". Essentially, we can enjoy it while it's not broken. go-fuzz itself supports both the libfuzzer mode and a custom-rolled approach. The latter design of go-fuzz is heavily inspired by the original AFL, which has not seen any love in years, while libfuzzer itself has also been deprecated recently. Overall, this results in a very sub-par support for SOTA fuzzing technologies, as there have been multiple advancements over the years that are both missing from libfuzzer and the internal go-fuzz implementation.
Detour: go-fuzz harness
As a reminder, here is a very simply setup for writing a fuzzing harness:
mkdir toy_fuzzer && cd toy_fuzzer
cat << EOF > toy_parser.go
package parser
func ParseComplex(data [] byte) bool {
if len(data) == 6 {
if data[0] == 'F' &&
data[1] == 'U' &&
data[2] == 'Z' &&
data[3] == 'Z' &&
data[4] == 'I' &&
data[5] == 'N' &&
data[6] == 'G' {
panic("Critical bug!")
}
}
return false
}
EOF
cat << EOF > toy_parser_fuzz.go
package parser
func Fuzz(data []byte) int {
ParseComplex(data)
return 0
}
EOF
# Init package
go mod init parser
go mod tidy
go get github.com/dvyukov/go-fuzz/go-fuzz-dep
# Install go-fuzz-build globally
go install github.com/dvyukov/go-fuzz/go-fuzz@latestA toy example on how to set up a simple fuzzer repo
To now get this fuzzer up and running, we simply can execute the following:
# Compile the fuzzer into a library
go-fuzz-build -libfuzzer -o parserFuzzer.a -func "Fuzz"
# Compile the harness as the library houses a LLVMFuzzerTestOneInput entrypoint
clang -fsanitize=fuzzer,address,undefined parserFuzzer.a -o parserFuzzer.libfuzzer
./parserFuzzer.libfuzzerAnd sure enough, we can quickly find the "critical bug" ;):
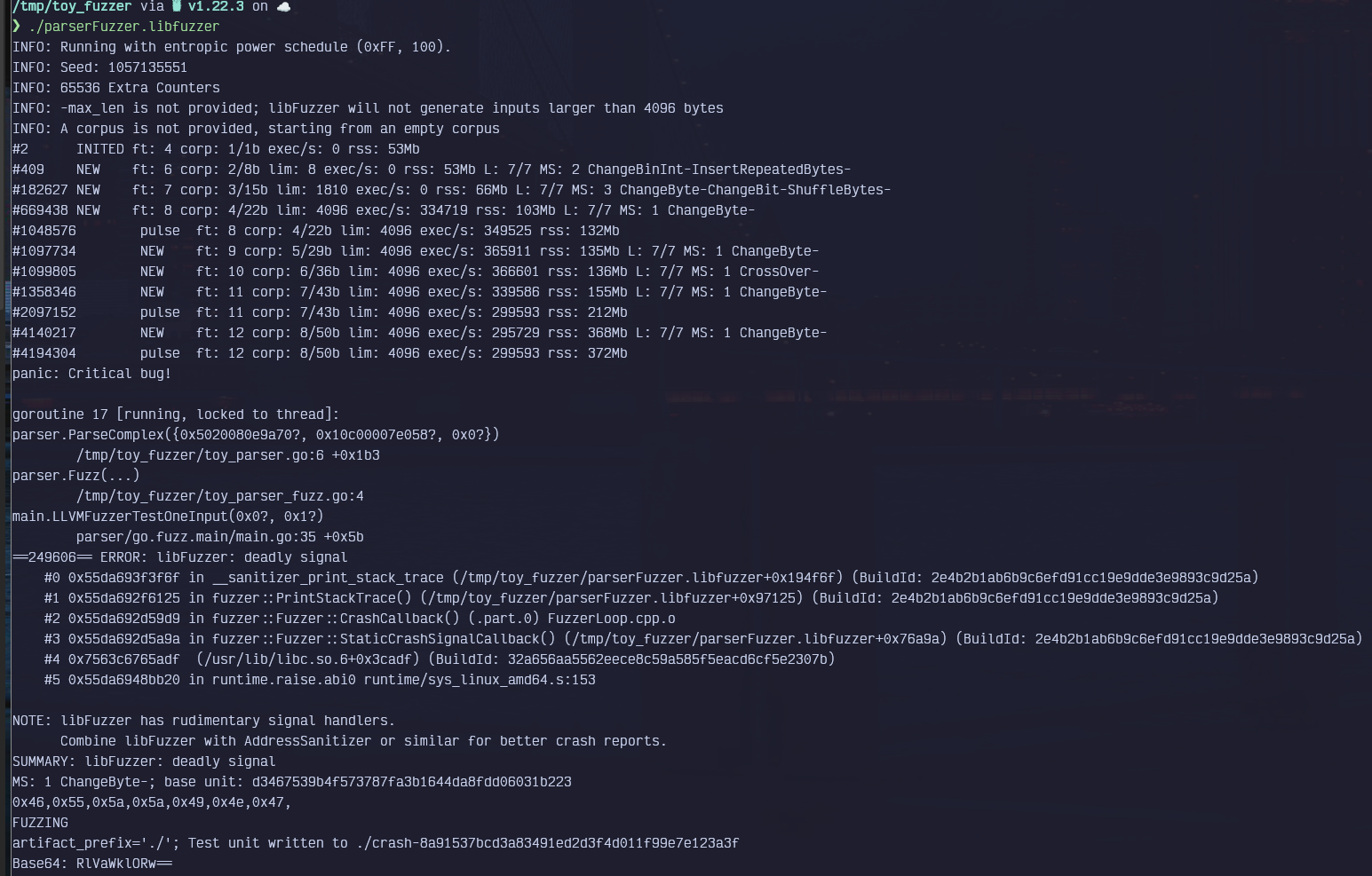
libfuzzer mode fuzzingThe above shows the "libfuzzer-way" of fuzzing the code. If we want to use the "native" approach offered by go-fuzz itself, we have to change our compilation to:
# Omit the -libfuzzer
go-fuzz-build -o parserFuzzer_native.a -func "Fuzz"
# Execute the fuzzer
go-fuzz -bin parserFuzzer_native.a -procs 1Interestingly enough, go-fuzz was struggling with this a little bit, and it took quite a bit to trigger the bug despite the "cover"-age of go-fuzz showing the same value as the libfuzzer version pretty quickly:
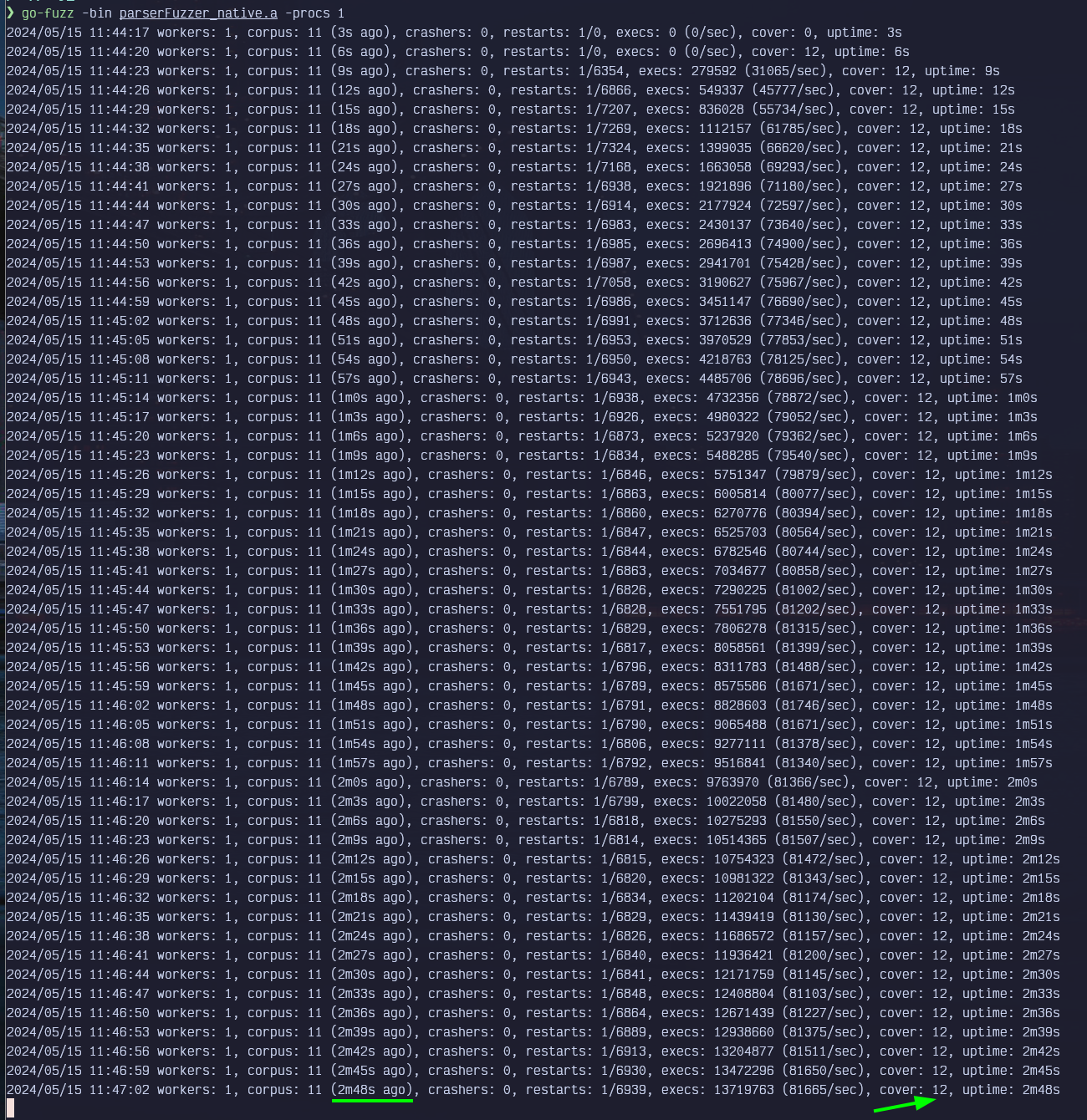
go-fuzz approach to fuzzingI tried spinning up 4 working and let it work on the problem for like another 2 minutes, and it still was unable to find the crash here, so point in case for libfuzzer, while being in at best "maintenance" mode, it can still be quite handy to have at hand!
go114-fuzz-build
Following go-fuzz, go114-fuzz-build was introduced to create fuzzing harnesses compatible with libFuzzer. This tool was originally designed for Go 1.14, aiming to leverage libFuzzer's capabilities that were available since that version. However, with libFuzzer itself being deprecated, its usefulness is starting to deteriorate, and it offers no real benefit over using go-fuzz presently...
The present?
Native Fuzzing in Go 1.18+
With the release of Go 1.18, fuzzing was natively integrated into the language, as detailed in the Go documentation. This new approach integrates fuzzing directly into Go's testing framework, making the syntax similar to that of unit tests. This design obviously aims to make fuzzing more accessible to developers while reducing the need for external/third-party tooling. Furthermore, the fuzzing engine does not seem to be based on libfuzzer (good!). That said, not too many details like technical documentation seem to have published since it emerged as a native feature…
Detour: Native fuzzing for the earlier example:
We have to add a new file to our directory from earlier:
cat << EOF > toy_parser_fuzz_test.go
package parser
import (
"testing"
)
func FuzzNative(f *testing.F) {
// To add to the corpus we can use:
// f.Add([]byte("data"))
f.Fuzz(func(t *testing.T, data []byte) {
ParseComplex(data)
})
}
EOFNext, to run this newly created fuzz test, we simply run:
go test -fuzz FuzzNativeAnd pretty much immediately we get the expected result, even faster than what we were getting with the libfuzzer approach:
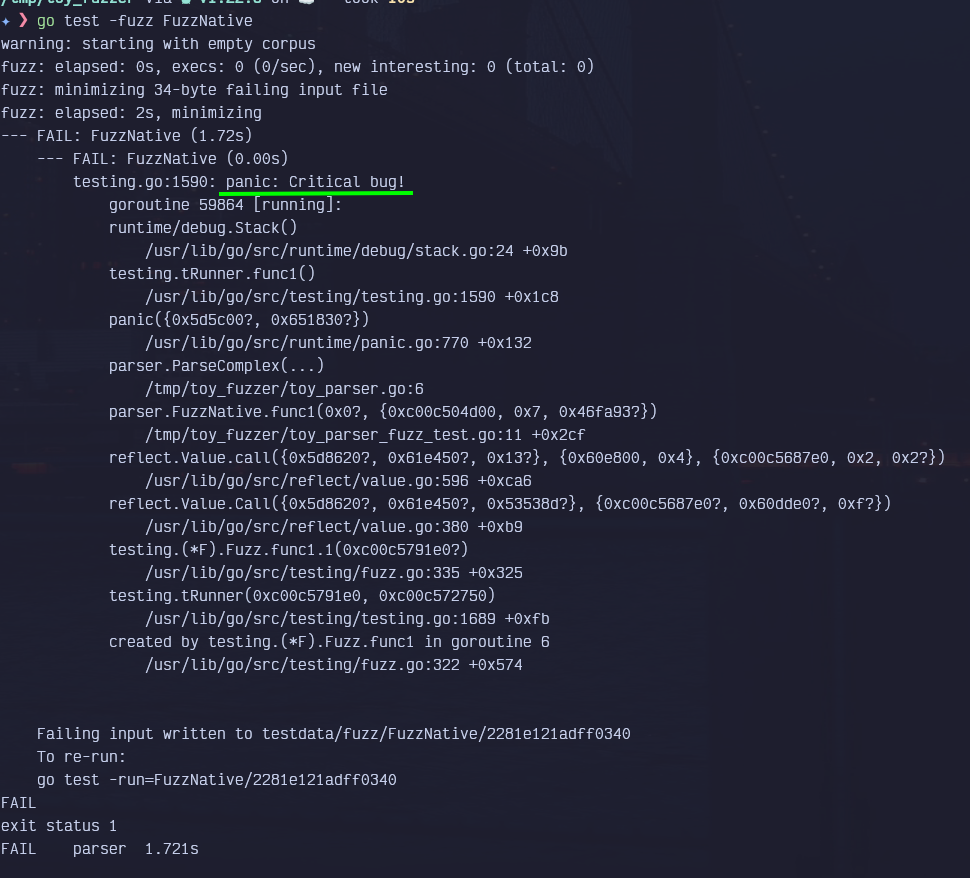
While I enjoy the quick finding, I as a security researcher, don't enjoy the "test view" of the results. IMHO, the stack trace houses a lot of uninteresting information and the format just irks me, but that's very subjective anyway. Lastly, while the finding appeared quick, I don't seem to have any flexibility whatsoever to structure my fuzzing campaign. No tweaking, no flags? It's made usable at the cost of flexibility? Which one am I supposed to use at the end of the day?
Coverage Instrumentation and Design Draft
That said, the design draft for Go fuzzing provides some insights but lacks detailed technical information on its implementation. The issue for coverage instrumentation, opened eight years ago, remains open, even though fuzzing has been released. Another related issue, add fuzz test support, has been closed, mentioning its inclusion in Go 1.18. Overall, this state of affairs sums up the state of fuzzing in Go for me quite well: "Fuzzing is supported but not really but then again it works natively but only to a degree"
Alternative Tools
go-118-fuzz-build
There exists go-118-fuzz-build, a continuation of go-114-fuzz-build, which again aims to support compiling native Golang fuzzers down to a libfuzzer target. It seems to mainly target those who rely on libfuzzer running in CI or continuous environments. Again, due to the deprecation of libfuzzer in combination with that continuous fuzzing for the CI could have been a nice feature for a native fuzzing implementation, it feels like this is yet again just more tape to barely hold things.
AFL++ Integration
Efforts to integrate AFL++ with Go, such as the project go-afl-build, have been largely experimental and for the most part abandoned, which really is a shame as AFL++ is the de-facto gold standard for fuzzing C/C++ applications, is actively maintained and gets new proven to be good features now and then.
Honorable mention: go-fuzz-headers
Not really a fuzzer or fuzzing-wrapper, but a nifty little helper that brings the helpful FuzzedDataProvider to the Go ecosystem, which makes structured-fuzzing a lot easier
The future?
Based on the scarce/fragmented landscape for Go fuzzing, what can we expect in the (near) future?
Native Go Fuzzing: Is It Advancing?
A look at the open issues related to fuzzing in the Go repository shows a slow pace of development, with only two issues closed in 2023. Even without the fuzz label, the progress appears underwhelming TBH. I hope there's more stuff happening under the hood, and if yes, I'd love more transparency about upcoming changes/plans! Also, looking at the fuzzing trophy case that lists bugs found by the native fuzzing approach... the results are not that impressive and are suggesting either limited usage of this feature, a limited effectiveness, or just maybe nobody is reporting any juicy bugs. Finally, I actually hope the trophy case is just not updated though :p...
Is the bigger picture that bleak?
The above ramblings seem to paint a very bleak picture, and could just be that's how I felt researching this on some spring morning a couple of days ago. One ray of hope that I stumbled across eventually was the "vuln list" that shows that in 2024 alone there have been multiple CVEs assigned to various Go packages, meaning the bugs are there but are they findable by current fuzzing means?
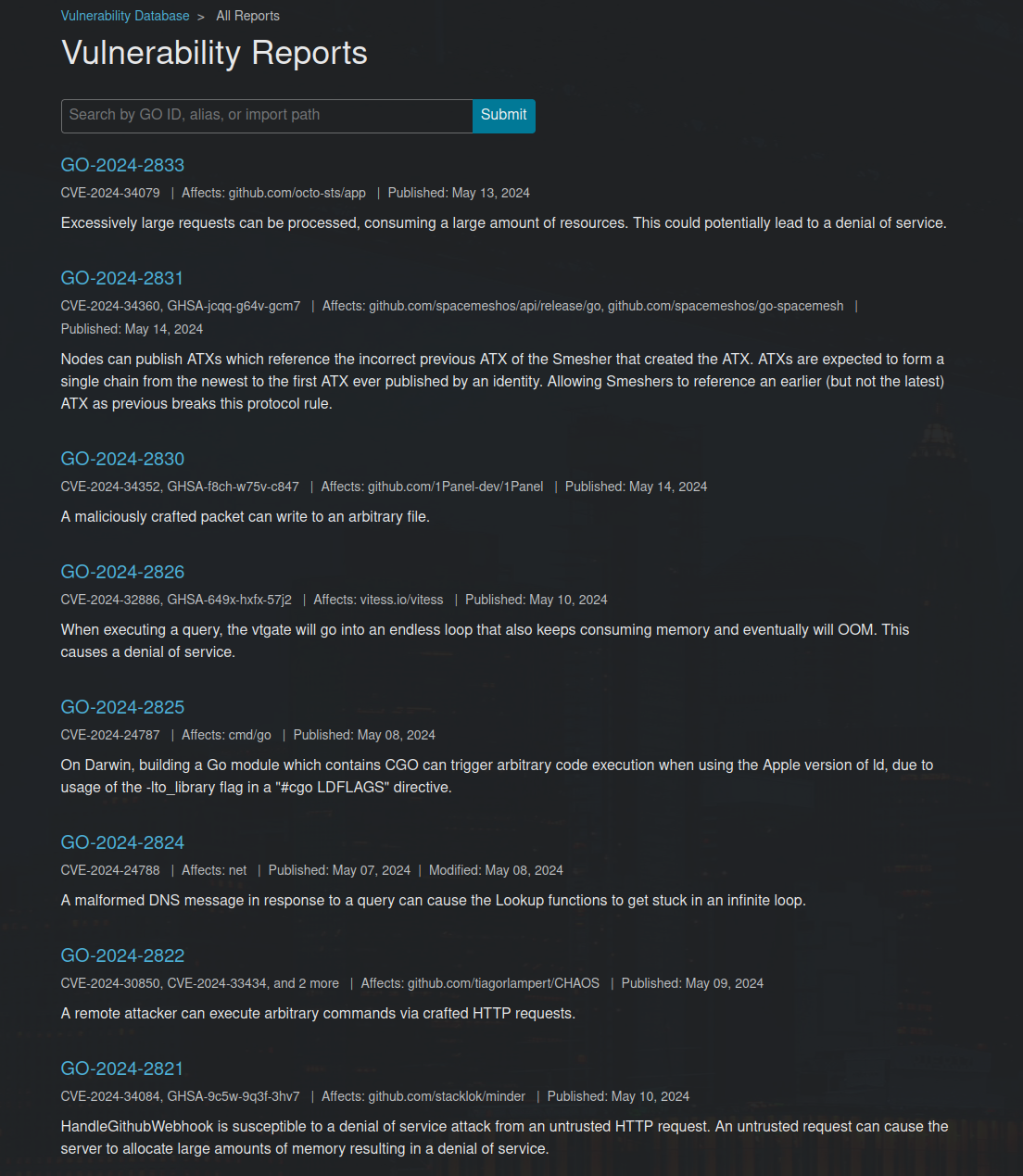
I did a rather quick analysis of some of the more recent findings, which let me come up with the following bug buckets:
- Denial of Service (DoS):
- CVE-2023-39325 - HTTP/2 servers can encounter excessive resource consumption due to rapid request creation and resetting by a malicious client.
- CVE-2024-24768 - Parsing malformed JSON in the
protojsonpackage can lead to infinite loops and resource exhaustion. - CVE-2023-29407 - A maliciously crafted image can cause excessive CPU consumption in decoding.
- Directory Traversal:
- CVE-2022-23773 - The go command can misinterpret branch names as version tags, potentially allowing access control bypass.
- CVE-2024-25712 - The
httpSwaggerpackage's HTTP handler provides WebDAV access to an in-memory file system, allowing directory traversal and arbitrary file writes.
- Authentication Bypass:
- CVE-2023-50424 - An unauthenticated attacker can obtain arbitrary permissions within an application using the cloud-security-client-go package under certain conditions.
- Command Injection:
- CVE-2024-22197 - Remote command execution in the Nginx-UI admin panel
- CVE-2022-31249 - Specially crafted commands can be passed to Wrangler that will change their behavior and cause confusion when executed through Git, resulting in command injection in the underlying host
- Cryptographic Issues:
- CVE-2023-48795 - A protocol weakness allows MITM attackers to compromise the integrity of the SSH secure channel before it is established.
- CVE-2023-39533 - Large RSA keys can lead to resource exhaustion attacks in the
libp2ppackage.
- Information Disclosure:
- CVE-2023-45825 - Custom credentials used with the
ydb-go-sdkpackage may leak sensitive information via logs. - CVE-2023-23631 - Reading malformed
HAMTsharded directories can cause panics and virtual memory leaks
- CVE-2023-45825 - Custom credentials used with the
- Code execution:
- CVE-2023-29405 - go command may execute arbitrary code at build time when using
cgo. - CVE-2023-39323 - Line directives (
//line) can be used to bypass the restrictions on//go:cgo_directives, allowing blocked linker and compiler flags to be passed during compilation. This can result in unexpected execution of arbitrary code when running "go build".
- CVE-2023-29405 - go command may execute arbitrary code at build time when using
Most of these examples given here seem like bugs that could be critical but are typically not found by traditional fuzzing means, except for the DoS category.
Why Classic Memory Corruption Bugs Are Not Expected in Go
I by no means am an expert of the Go language, nor did I write extensive code in Go itself. From what I was able to learn, though, I can say the following. Go, by design, mitigates many of the classic memory corruption vulnerabilities prevalent in languages like C and C++. This is due to several key language features:
- Garbage Collection: Go manages memory automatically through garbage collection, reducing the risk of memory leaks, double frees, and use-after-free errors that are common in manually managed memory environments.
- Bounds Checking: Go includes automatic bounds checking on array and slice accesses. This means that accessing elements outside the valid range of an array or slice will result in a runtime panic, rather than undefined behavior, which is often the case of buffer overflows in languages like C.
- Type Safety: Go's strong and static type system ensures that many types of invalid memory accesses are caught at compile time, preventing a wide range of type-related memory corruption bugs.
- No Pointer Arithmetic: Unlike C and C++, Go does not support pointer arithmetic, which is a common source of buffer overflows and other memory corruption issues.
Given these features, traditional fuzzing techniques aimed at uncovering memory corruption issues, such as buffer overflows and dangling pointers, are less effective in Go. Instead, the focus should be on higher-level logic errors, improper input handling, and other application-level vulnerabilities, like we have also seen in the glimpse of the recent CVEs earlier. The nature of the language itself paired with what type of programs are typically written in Go (client-server constructs, backends, web services, concurrent workers, ...) needs us to rethink and adapt.
Go bug classes - a new horizon?
As iterated before, Go was designed with safety and simplicity in mind, addressing many of the pitfalls inherent in languages like C and C++. The major key differences are memory safety, type safety, and a good native concurrency model. Due to these differences, traditional fuzzing techniques that target memory corruption vulnerabilities are less effective in Go. Instead, we should focus on higher-level logic and input validation issues that are more relevant to Go applications and are more akin to "traditional" web vulnerabilities. To understand the types of vulnerabilities Go fuzzing should target, consider these examples:
- Path traversal vulnerabilities occur when an application does not properly sanitize user input used in file paths, allowing attackers to access restricted directories and files. In the example, an attacker could manipulate the
fileparameter to access sensitive files outside the intended directory. A recent vulnerability like this has been observed on Windows and published under CVE-2023-1568
package main
import (
"net/http"
"path/filepath"
)
func serveFile(w http.ResponseWriter, r *http.Request) {
filename := r.URL.Query().Get("file")
safePath := filepath.Join("/safe/directory", filename)
http.ServeFile(w, r, safePath)
}
- Command injection vulnerabilities arise when an application executes system commands constructed from user input without proper validation, allowing arbitrary command execution. Here, an attacker could provide a malicious
cmdparameter to execute arbitrary commands on the server. A real-life example for this also from last year: CVE-2023-1839
package main
import (
"os/exec"
"net/http"
)
func executeCommand(w http.ResponseWriter, r *http.Request) {
cmd := r.URL.Query().Get("cmd")
out, err := exec.Command(cmd).Output()
if err != nil {
http.Error(w, "Command execution failed", http.StatusInternalServerError)
return
}
w.Write(out)
}
- SQL injection vulnerabilities occur when user input is directly included in SQL queries without proper escaping or parameterization, allowing attackers to manipulate database queries. In this scenario, an attacker could inject malicious SQL through the
user_idparameter to manipulate the query. Here, an even more recent real-life example: CVE-2024-27289
package main
import (
"database/sql"
"net/http"
_ "github.com/go-sql-driver/mysql"
)
func queryDatabase(w http.ResponseWriter, r *http.Request) {
userID := r.URL.Query().Get("user_id")
db, _ := sql.Open("mysql", "user:password@/dbname")
rows, err := db.Query("SELECT name FROM users WHERE id = " + userID)
if err != nil {
http.Error(w, "Database query failed", http.StatusInternalServerError)
return
}
defer rows.Close()
for rows.Next() {
var name string
rows.Scan(&name)
w.Write([]byte(name))
}
}
Among these, a bunch of other injection type vulnerabilities exist, a non exhaustive-list would be: LDAP, CSV, XML, XSS, or any other popular templating engine…
Fuzzing++?
An additional measure I'd love to see support (natively) next to traditional fuzzing means are more nuanced ways to test APIs, more akin to specialized unit-tests, such as:
- Idempotency fuzzing, which ensures that multiple applications of the same operation produce the same result, crucial for APIs and distributed systems.
package main
import (
"fmt"
"strings"
)
func sanitize(input string) string {
return strings.ToLower(strings.TrimSpace(input))
}
func main() {
input := " TEST "
result1 := sanitize(input)
result2 := sanitize(result1)
if result1 != result2 {
fmt.Println("Sanitization is not idempotent!")
} else {
fmt.Println("Sanitization is idempotent.")
}
}
- Differential fuzzing involves providing the same inputs to multiple implementations of a function or algorithm and checking for differences in outputs, indicating potential bugs.
package main
import (
"crypto/sha256"
"fmt"
)
func hash1(data []byte) []byte {
h := sha256.New()
h.Write(data)
return h.Sum(nil)
}
// Assume this differs from hash1 in a way that a different API is being used
func hash2(data []byte) []byte {
h := sha256.New()
h.Write(data)
return h.Sum(nil)
}
func main() {
data := []byte("test")
hashA := hash1(data)
hashB := hash2(data)
if fmt.Sprintf("%x", hashA) != fmt.Sprintf("%x", hashB) {
fmt.Println("Hashes do not match!")
} else {
fmt.Println("Hashes match.")
}
}
There's likely other ways, but this highlights that could and should consider new ways to ensure code is as bug-free as possible.
Conclusion
The Go fuzzing ecosystem is indeed in a weird spot. With native fuzzing capabilities introduced in Go 1.18, there is potential, but the progress and adoption seem slow. The legacy tools are either deprecated or experimental, and the current native solution lack proven features or new ideas for widespread success stories. Even a strategic marriage with AFL++ (if possible in the first place) would be great, despite the interesting bug classes being so different. That said, the need for more specialized fuzzing techniques and better tooling remains critical for advancing Go fuzzing, IMHO.
For anyone looking to fuzz Go packages today, the native approach, despite its limitations, seems the most viable option. However, there is significant room for improvement, and the community needs more robust and actively maintained tools to make Go fuzzing truly effective. Again, this is by no means just a rant to lash out at people, but I think we as a community can do better here, me included, and I'm seriously looking forward to what may be released in the future.
Finally, if you made it up to here, I'd be happy to discuss further with you what could be done. Or if my "hot-take" here is completely tone-deaf, I'd be just as happy to hear about why I'm wrong :)!!