

Preface
This quick article will give a short introduction on what fuzzers are, how they work and how to properly setup the afl - american fuzzy lop fuzzer to find flaws in arbitrary projects.
Well known alternatives to afl (for the same or other purposes):
- boofuzz: Network Protocol Fuzzing for Humans
- Googles - OSS-Fuzz - Continuous Fuzzing for Open Source Software
- libfuzzer
- and many more
What is fuzzing?
In short, we can define fuzzing as the following
"Fuzzing is a Black Box software testing technique, which basically consists in finding implementation bugs using malformed/semi-malformed data injection in an automated fashion."
This approach can be done on the whole application, specific protocols and even single file formats. Depending on the attack vector the output changes obviously and can lead to a varying number of bugs.
Cool stuff about fuzzing
- simple design, hence a basic fuzzer can be easily implemented from scratch
- finds possible bugs/flaws via a random approach, which often are overlooked by human QA
- Combinations of different input mutations and symbolic execution!
Not so cool stuff...
- Often 'simple bugs' only
- black box testing makes it difficult to evaluate impact of found results
- Many fuzzers are limited to a certain protocol/architecture/...
How to set up afl for fuzzing with exploitable and gdb
Let's get right into setting up our environment... Not much else to say before that.
Juicy stuff ahead!
Get afl running by cloning the repos
git clone https://github.com/mirrorer/afl.git afl
cd afl
make && sudo make install
su root
echo core >/proc/sys/kernel/core_pattern
cd /sys/devices/system/cpu && echo performance | tee cpu*/cpufreq/scaling_governor
exit
sudo apt install gnuplot
# --------------------------------------------------------------------------- #
git clone https://github.com/rc0r/afl-utils.git afl-utils
cd afl-utils
sudo python setup.py install
# --------------------------------------------------------------------------- #
# -----------------------------------optional-------------------------------- #
# --------------------------------------------------------------------------- #
# check the official git repo for needed/supported architectures #
git clone https://github.com/shellphish/afl-other-arch.git afl-qemu-patch
cd afl-qemu-patch
./build.sh <list,of,arches,you,need>
Once installed you're ready to start fuzzing your favorite project. We'll come to this in the next paragraph by picking a random github project. I'll provide the used afl commands for the later shown results at the end of the article, but won't name the fuzzed repository for privacy reasons.
Instrument afl and start pwning help to secure GitHub repositories
If the source code is available compile it with CC=afl-gcc make, or CC=afl-gcc cmake CMakeLists.txt && make to instrument afl.
$ cd targeted_application
CC=afl-gcc cmake CMakeLists.txt && make
-- The C compiler identification is GNU 5.4.0
-- Check for working C compiler: /usr/local/bin/afl-gcc
-- Check for working C compiler: /usr/local/bin/afl-gcc -- works
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Detecting C compile features
-- Detecting C compile features - done
-- Configuring done
-- Generating done
-- Build files have been written to: /home/lab/Git/<target>
Scanning dependencies of target <target>
[ 14%] Building C object <target>
afl-cc 2.52b by <lcamtuf@google.com>
afl-as 2.52b by <lcamtuf@google.com>
[+] Instrumented 5755 locations (64-bit, non-hardened mode, ratio 100%).
[ 28%] Linking C static library <target>
[ 28%] Built target <target>
Scanning dependencies of target md2html
[ 42%] Building C object <target>
afl-cc 2.52b by <lcamtuf@google.com>
afl-as 2.52b by <lcamtuf@google.com>
[+] Instrumented 165 locations (64-bit, non-hardened mode, ratio 100%).
[ 57%] Building C object <target>
afl-cc 2.52b by <lcamtuf@google.com>
afl-as 2.52b by <lcamtuf@google.com>
[+] Instrumented 8 locations (64-bit, non-hardened mode, ratio 100%).
[ 71%] Building C object <target>
afl-cc 2.52b by <lcamtuf@google.com>
afl-as 2.52b by <lcamtuf@google.com>
[+] Instrumented 58 locations (64-bit, non-hardened mode, ratio 100%).
[ 85%] Building C object <target>
afl-cc 2.52b by <lcamtuf@google.com>
afl-as 2.52b by <lcamtuf@google.com>
[+] Instrumented 407 locations (64-bit, non-hardened mode, ratio 100%).
[100%] Linking C executable <target>
afl-cc 2.52b by <lcamtuf@google.com>
[100%] Built target <target>
To start local application fuzzing we can execute afl via the following command chain:
$ afl-fuzz -i input_sample_dir -o output_crash_dir ./binary @@
-i defines a folder which holds sample data for the fuzzer to use
-o defines a folder where afl will save the fuzzing results
./binary describes the targeted application
If you have the resources to start more processes of afl keep in mind that each process takes up one CPU core and pretty much leverages 100% of its power. To do so a change up of the afl command chain is needed!
$ afl-fuzz -i input_sample_dir -o output_crash_dir -M master ./binary @@
$ afl-fuzz -i input_sample_dir -o output_crash_dir -S slaveX ./binary @@
The only difference between the master and slave modes is that the master instance will still perform deterministic checks. The slaves will proceed straight to random tweaks. If you don't want to do deterministic fuzzing at all you can straight up just spawn slaves. For statistic- and behavior-research having one master process is always a nice thing tho.
Note: For programs that take input from a file, use '@@' to mark the location in the target's command line where the input file name should be placed. The fuzzer will substitute this for you.
Note2: You can either provide an empty file in the input_sample_dir and let afl find some fitting input, or give some context specfic input for the program you're fuzzing that is parsable!
To instrument afl-QEMU for blackbox fuzzing install needed dependencies sudo apt-get install libtool libtool-bin automake bison libglib2.0-dev zlib1g-dev and execute ./build_qemu_support.sh within the afl repo ~/afl/qemu_mode/.
Next up compile target program without CC=afl-gcc and change the afl-fuzz command chain to:
$ afl-fuzz -Q -i input_sample_dir -o output_crash_dir -M master ./binary @@
The emulation should work on its own already at this point. To support different, more exotic architectures in afl apply said patch from the prep work above!
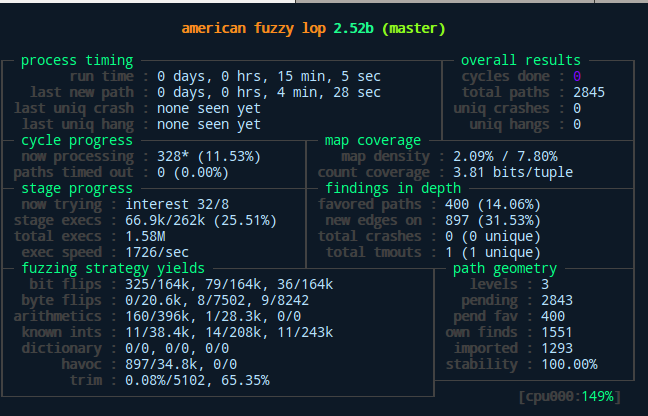
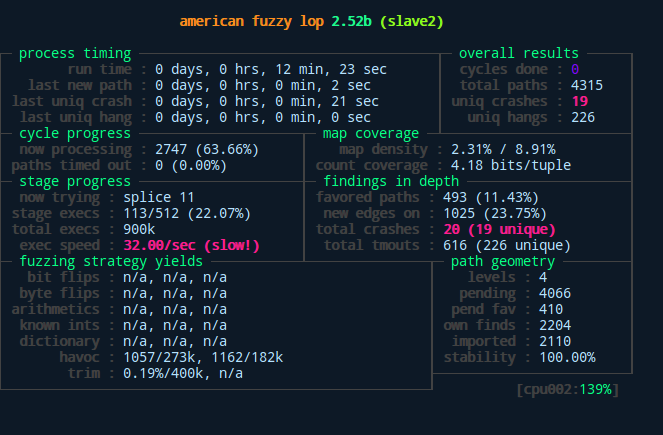
Above we can see the difference between master and slaves as well as the general interface of afl after starting the fuzzing process. As displayed here, our slave found a bunch of unique crashes after only measly 12 minutes with its random fuzzing behavior. The master slave on the other hand didn't quite catch up to that yet...
The crashes and hangs can be manually examined within the output_crash_dir/process_name/crashes and output_crash_dir/process_name/hangs folders. Since this manual labor is neither interesting nor effective some smart people offered us the afl-utils package, which automatizes the crash analysis and pairs it with a sweet output from a gdb script.
Automatic analysis of produced crashes
To automatically collect and analysis crashes with afl-collect + exploitable from the afl-utils package do the following while the fuzzing processes are still up and running:
$ afl-collect -d crashes.db -e gdb_script -r -rr ./output_crash_dir_from_afl_fuzz ./afl_collect_output_dir -j 8 -- /path/to/target
The only two parameters to change here are the ./output_crash_dir_from_afl_fuzz, which is the folder where the afl-fuzz process stores its output. Next up is the /path/to/target, which is the fuzzed application. Depending on your hardware you can adjust the -j 8 parameters, which is used to specify the amount of threads to analyze the output. If everything works accordingly you'll stumble upon an output like this:
afl-collect -d crashes.db -e gdb_script -r -rr ./out ./output_aflc -j 8 -- ./path/to/target
afl-collect 1.33a by rc0r <hlt99@blinkenshell.org> # @_rc0r
Crash sample collection and processing utility for afl-fuzz.
[*] Going to collect crash samples from '/home/lab/Git/code/path/to/target/out'.
[!] Table 'Data' not found in existing database!
[*] Creating new table 'Data' in database '/home/lab/Git/code/path/to/target/crashes.db' to store data!
[*] Found 3 fuzzers, collecting crash samples.
[*] Successfully indexed 56 crash samples.
*** Error in `/home/lab/Git/code/path/to/target': double free or corruption (out): 0x000000000146c5a0 ***
======= Backtrace: =========
/lib/x86_64-linux-gnu/libc.so.6(+0x777e5)[0x7f0acaeb67e5]
/lib/x86_64-linux-gnu/libc.so.6(+0x8037a)[0x7f0acaebf37a]
/lib/x86_64-linux-gnu/libc.so.6(cfree+0x4c)[0x7f0acaec353c]
/home/lab/Git/code/path/to/target(<func_a>+0x93fd)[0x4627ed]
/home/lab/Git/code/path/to/target(<func_b>+0xaa)[0x40e75a]
/home/lab/Git/code/path/to/target(main+0x4c4)[0x4017f4]
/lib/x86_64-linux-gnu/libc.so.6(__libc_start_main+0xf0)[0x7f0acae5f830]
/home/lab/Git/code/path/to/target(_start+0x29)[0x402169]
======= Memory map: ========
00400000-00401000 r--p 00000000 fd:00 38669039 /home/lab/Git/code/path/to/target/
00401000-00476000 r-xp 00001000 fd:00 38669039 /home/lab/Git/code/path/to/target/l
00476000-0048a000 r--p 00076000 fd:00 38669039 /home/lab/Git/code/path/to/target/
0048a000-0048b000 r--p 00089000 fd:00 38669039 /home/lab/Git/code/path/to/target
0048b000-0048c000 rw-p 0008a000 fd:00 38669039 /home/lab/Git/code/path/to/target
01461000-0148a000 rw-p 00000000 00:00 0 [heap]
7f0ac4000000-7f0ac4021000 rw-p 00000000 00:00 0
7f0ac4021000-7f0ac8000000 ---p 00000000 00:00 0
7f0acac29000-7f0acac3f000 r-xp 00000000 fd:00 40899039 /lib/x86_64-linux-gnu/libgcc_s.so.1
7f0acac3f000-7f0acae3e000 ---p 00016000 fd:00 40899039 /lib/x86_64-linux-gnu/libgcc_s.so.1
7f0acae3e000-7f0acae3f000 rw-p 00015000 fd:00 40899039 /lib/x86_64-linux-gnu/libgcc_s.so.1
7f0acae3f000-7f0acafff000 r-xp 00000000 fd:00 40895232 /lib/x86_64-linux-gnu/libc-2.23.so
7f0acafff000-7f0acb1ff000 ---p 001c0000 fd:00 40895232 /lib/x86_64-linux-gnu/libc-2.23.so
7f0acb1ff000-7f0acb203000 r--p 001c0000 fd:00 40895232 /lib/x86_64-linux-gnu/libc-2.23.so
7f0acb203000-7f0acb205000 rw-p 001c4000 fd:00 40895232 /lib/x86_64-linux-gnu/libc-2.23.so
7f0acb205000-7f0acb209000 rw-p 00000000 00:00 0
7f0acb209000-7f0acb22f000 r-xp 00000000 fd:00 40895230 /lib/x86_64-linux-gnu/ld-2.23.so
7f0acb401000-7f0acb404000 rw-p 00000000 00:00 0
7f0acb42d000-7f0acb42e000 rw-p 00000000 00:00 0
7f0acb42e000-7f0acb42f000 r--p 00025000 fd:00 40895230 /lib/x86_64-linux-gnu/ld-2.23.so
7f0acb42f000-7f0acb430000 rw-p 00026000 fd:00 40895230 /lib/x86_64-linux-gnu/ld-2.23.so
7f0acb430000-7f0acb431000 rw-p 00000000 00:00 0
7ffd1292a000-7ffd1294b000 rw-p 00000000 00:00 0 [stack]
7ffd129c9000-7ffd129cc000 r--p 00000000 00:00 0 [vvar]
7ffd129cc000-7ffd129ce000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
As you can see we are getting a memory map and a backtrace for every crash. Since 56 crash samples were shown here I shortened the output to make it more easy to follow, but I hope it visualizes the point well enough. The real beefy part follows now tho!
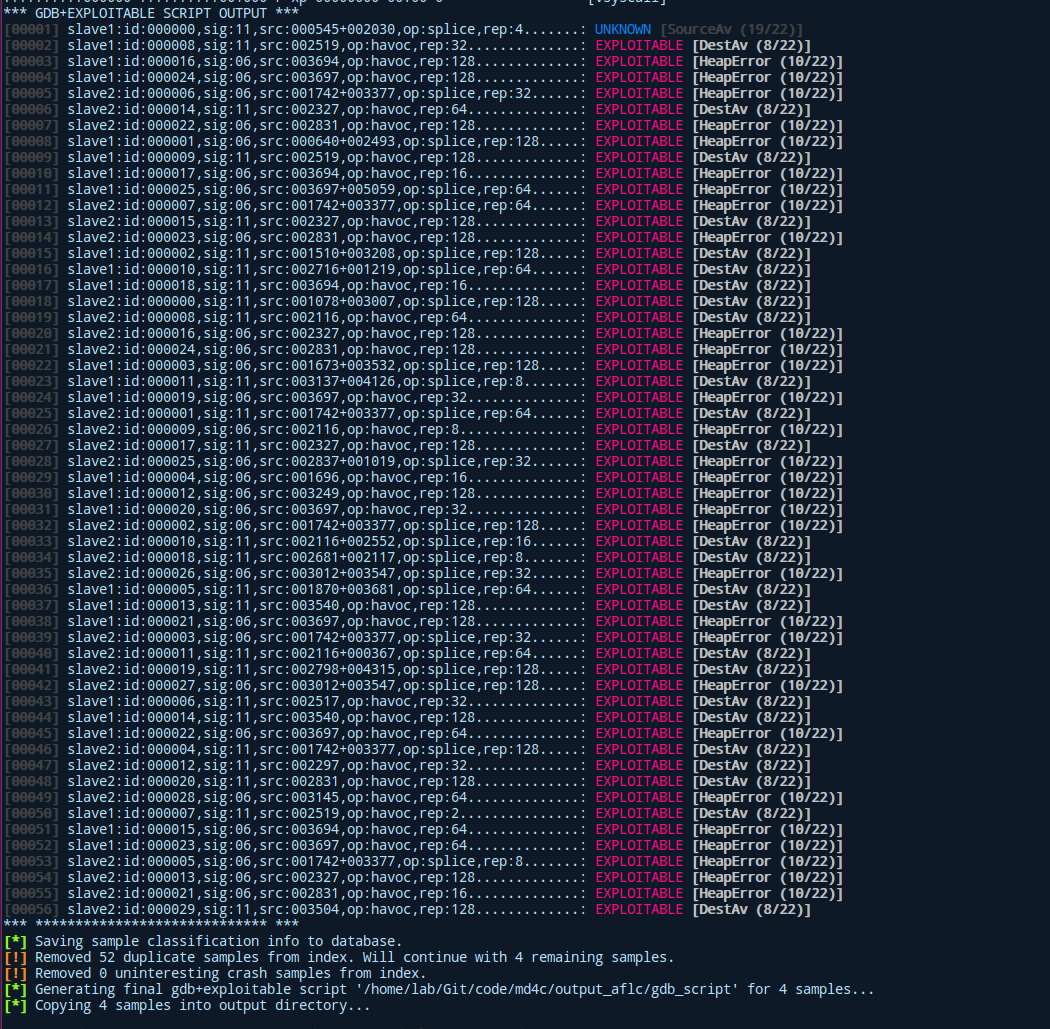
We're getting a complete overview about which process and what algorithm produced the error. Additionally, we can see the type of error coupled with an estimate on if it is exploitable or not. This gives us the chance dig deeper into the /afl_out/process_name/crash_id/, which is the used input to generate certain crash. We can then analyze it and try to conclude why crash occurred and maybe even produce one or multiple PoCs to abuse this behavior! A big disadvantage as of right now is that the exploitable script can only handle the most common architectures (x86 and ARM)! If you want to fuzz MIPS and PowerPC you need to fork the official repository and write your own logic for this!
Creating a PoC for our target application gets even easier, since we can directly jump into gdb and execute the crash on our fuzzed program! Simply run the following from the command line:
$ gdb ./fuzzed_application
gdb> run /path/to/crash_folder/crash_id
If we have a gdb extension like pwndbg, or gdb-peda inspecting what went wrong makes it a breeze!
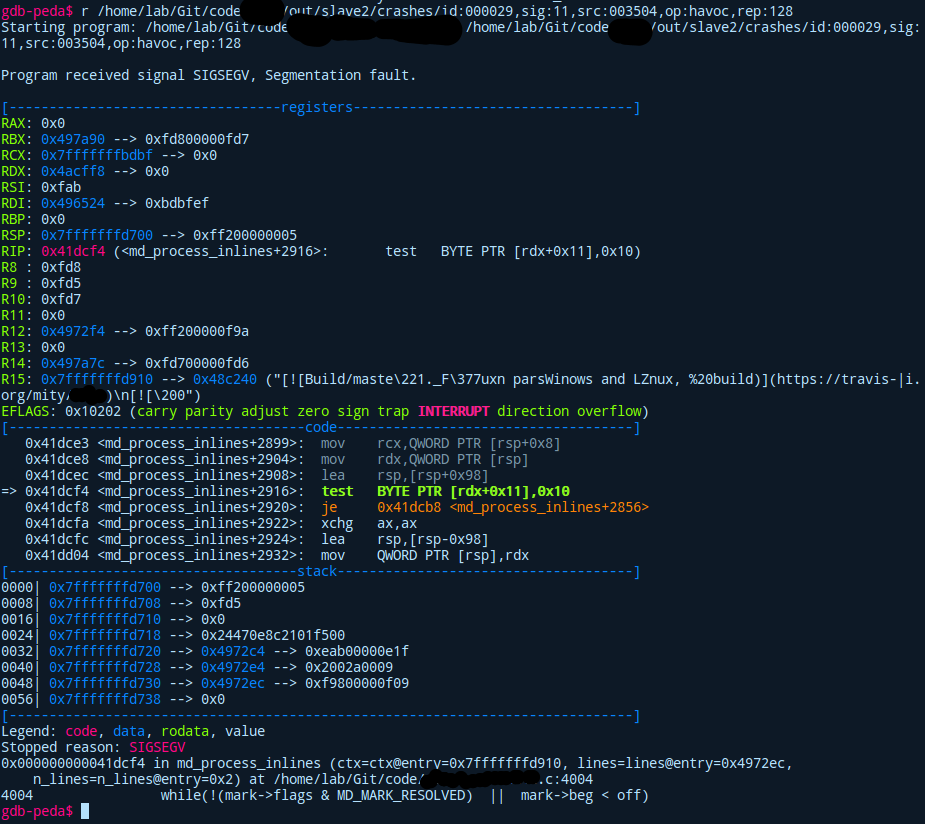
We can see the state of the register at one glance, while also getting an overview of which function crashed from the generated input. Now we could dig through the actual source code and find an answer on why the heck it crashed there. Why did the used input make the program go haywire? When finding an answer to this you can manually create a malformed input yourself and write a PoC for this.
To show you an overview on how much afl managed to deform my actual input for this crash I'll show you a side by side comparison of the original input and the one afl managed to produce to crash the target at the shown state:

Green bytes indicate that the files are still identical in that exact location. Red bytes indicate a difference, meaning afl mutated these bytes on its own accord (the ones on the right are the afl mutated ones).
Plotting the results from afl
For those among us, who are number and statistic nerds, afl provides a great feature for us! For every spawned process we get plottable data!
$ ls
crashes fuzz_bitmap fuzzer_stats hangs out plot_data queue
$ afl-plot --help
progress plotting utility for afl-fuzz by <lcamtuf@google.com>
This program generates gnuplot images from afl-fuzz output data. Usage:
/usr/local/bin/afl-plot afl_state_dir graph_output_dir
$ afl-plot . out
progress plotting utility for afl-fuzz by <lcamtuf@google.com>
[*] Generating plots...
[*] Generating index.html...
[+] All done - enjoy your charts!
This generates 3 plots:
- One for the execution speed/sec,
- One for the path coverage,
- And one for the found crashes and hangs.
For my particular fuzzing example for the sake of this article they look like this:
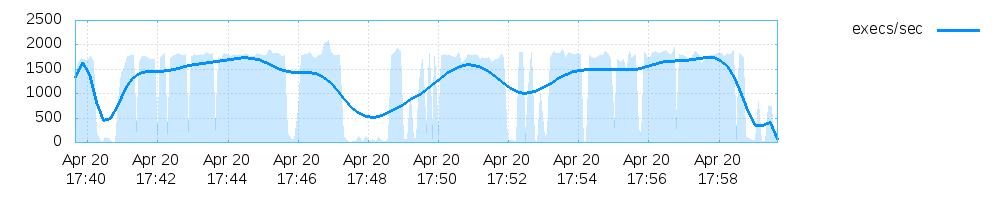
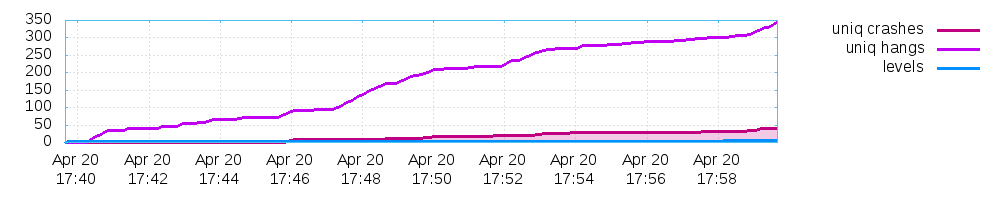
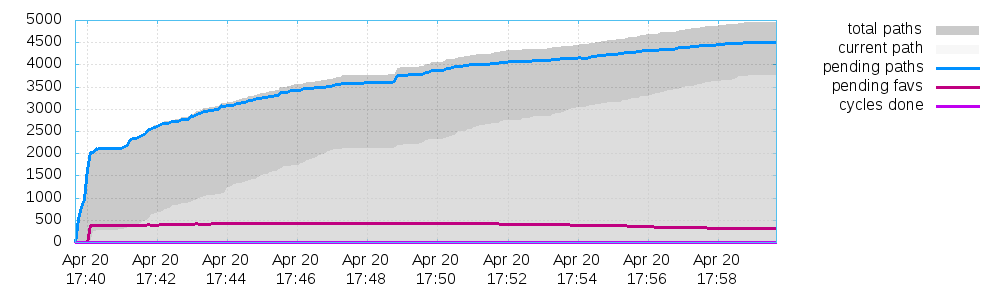
Final note on this: The stats shown in the afl fuzzing interface during the process fuzzing up until termination are stored for each process in a separate file too!
Conclusion
Fuzzing creates a powerful way to test projects on faults and flaws within the code. Depending on the used fuzzer the generated output can directly be used to deduct a possible exploit or PoC.
In the case of american fuzzy lop the base functionality already is great and definitely one of the faster fuzzing tools out there. The possible combination with afl-utils and the exploitable gdb script makes it even more awesome.
Last but not least it would be nice to test OSS, boofuzz or other not mentioned fuzzing frameworks to see how they can compete against each other.
I hope this quick and dirty overview showed that fuzzing is a strong approach to try to harden an application by finding critical flaws one could easily overlook with human QA. Please keep in mind that his demo presented here was done using a fairly broken repository.. If you start fuzzing things and not many crashes come around that's a good thing and you should not be sad about that, especially if it is your code, or widely used one :) !
With that in mind: Happy fuzzing!